A Hybrid information retriever with DuckDB

When it comes to information retrieval, vector search methods have demonstrated some good performance, especially when the embedding models have been fine-tuned on the target domain. However, these models can struggle when faced with “out-of-domain” tasks, where the data content is significantly different from what the model was trained on. When fine-tuning is not an option, full text search, which rely on lexical matching, can be effective. This is why some hybrid search approaches that combine the strengths of both semantic and lexical methods might be useful.
In this post, we’ll explore the implementation of search functions in Python with DuckDB, open-source embedding models, and use it on a DBpedia text dataset. We will also look at how we can combine scores to return the top $k$ matching results.
This post is largely motivated by [1], a paper by Sebastian Bruch, Siyu Gai and Amir Ingber : An Analysis of Fusion Functions for Hybrid Retrieval.
Outline
Hybrid search
Let us briefly describe the hybrid search flow. The process starts with a user query, which represents what the user is searching for, which leads to two distinct processes: semantic search over a dense vector store and lexical search over a sparse index. The resulting rankings/scores from both searches are then combined in a fusion process, leading to the hybrid ranking. Here is a schematic view of the hybrid search process:
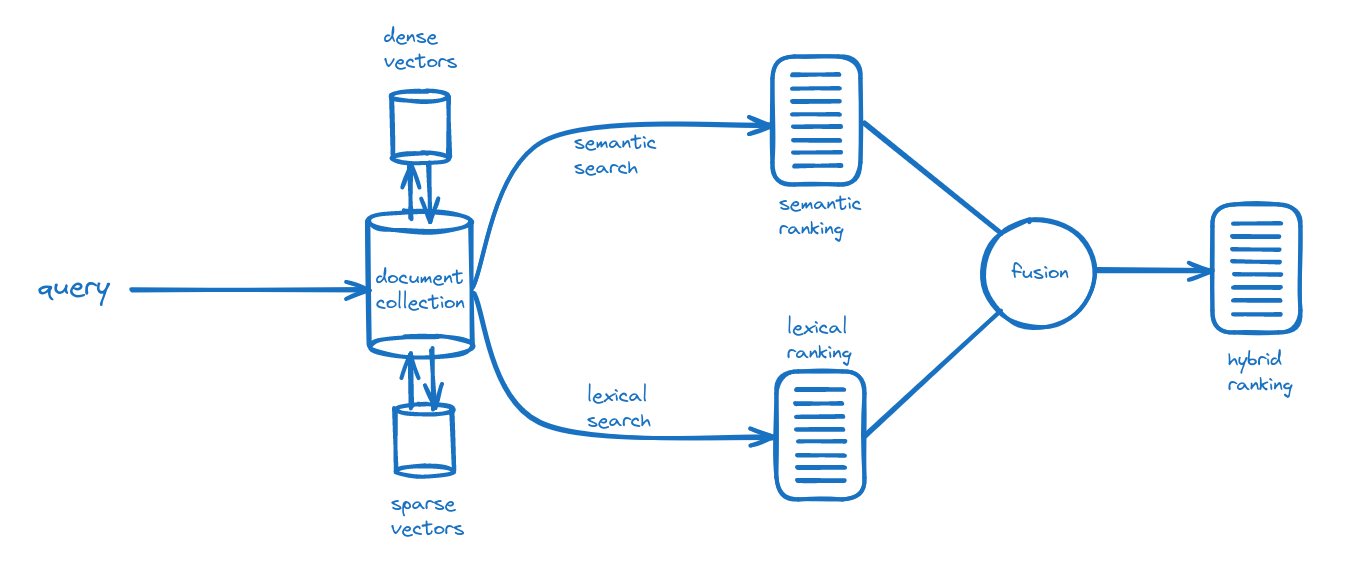
Let’s start by describing each of these search modules: semantic and lexical search. Note that hybrid search could also be used to mix distinct semantic approaches.
Semantic search
Semantic search is a method that seeks to understand the meaning and context of a search query. It uses natural language processing and machine learning techniques to analyze the relationships between words and concepts. It can be particularly useful for complex or ambiguous queries. Because it works by comparing dense vectors with a compact fixed size, we may refer to it as a dense retriever. Here is a brief description of dense embedding retrievers by Jaehyung Seo et al. [2]:
Dense-embedding-based information retrieval compares the semantic similarity between a query and a search target database in a latent space expressed as a continuous real value. Since this method exploits high-density expression in a small dimension, it can provide a fast retrieval speed and yield a result that is not excessively biased to a specific term. In other words, the meaning of the given input is interpreted according to the dynamically comprehended contextualized representation and the linguistic knowledge learned by the model during the pre-training process.
Asymmetric semantic search
Symmetric semantic search is used when the query and the entries in the corpus are similar in length and content, while asymmetric semantic search is used when the query is shorter and more focused than the entries in the corpus. In our case, we choose an asymmetric model. Here is a good explanation that can be found on the sentence-transformers website:
For symmetric semantic search your query and the entries in your corpus are of about the same length and have the same amount of content. An example would be searching for similar questions: Your query could for example be “How to learn Python online?” and you want to find an entry like “How to learn Python on the web?”. For symmetric tasks, you could potentially flip the query and the entries in your corpus.
For asymmetric semantic search, you usually have a short query (like a question or some keywords) and you want to find a longer paragraph answering the query. An example would be a query like “What is Python” and you want to find the paragraph “Python is an interpreted, high-level and general-purpose programming language. Python’s design philosophy …”. For asymmetric tasks, flipping the query and the entries in your corpus usually does not make sense.
As advised by the sentence-transformers website, we use a Pre-Trained MS MARCO Model. The exact version is : msmarco-distilbert-base-tas-b available on HuggingFace. Here is a short description from the Hugging Face model card:
DistilBert for Dense Passage Retrieval trained with Balanced Topic Aware Sampling (TAS-B)
We provide a retrieval trained DistilBert-based model (we call the dual-encoder then dot-product scoring architecture BERT_Dot) trained with Balanced Topic Aware Sampling on MSMARCO-Passage.
Although this model has been tuned for dot-product, we are going to use it for cosine similarity. The embedding dimension of the dense vectors is 768, with a rather small token input size of 512.
Sentence transformers
In the following, we use the Python package sentence-transformers to access the model from Hugging Face. Here is a short example of model instantiation with sentence-transformers:
import numpy as np
from sentence_transformers import SentenceTransformer
embedding_model = SentenceTransformer("msmarco-distilbert-base-tas-b")
search_txt = "who is Isaac Asimov"
embedding = embedding_model.encode(search_txt)
embedding[:10]
array([-0.5635936 , 0.23823887, -0.3518705 , -0.17575331, 0.07560609,
0.17918944, -0.0974636 , -0.23988722, 0.07106476, 0.02857562],
dtype=float32)
embedding.shape
(768,)
np.linalg.norm(embedding, ord=2)
10.973487
We observe that the embeddings are not normalized. This implies that in DuckDB, the cosine similarity function (array_cross_product(array1, array2)) will be used instead of the lighter inner product (array_inner_product(array1, array2)).
The model weights are being cached on the local disk on the first use by sentence-transformers. The PyTorch model binary file is about 265 MB size, this is a small model. If you want to use your GPU, you just need to install PyTorch for GPU first in your environment. Beware that it requires specific versions of CUDA on your system.
Semantic chunking
To ensure that the input text does not exceed the maximum token size of the model, we use the semchunk Python library to split the text into smaller, semantically meaningful chunks. This approach allows us to preserve the meaning of the original text while also making it compatible with the model’s token size limit.
Here is a example usage of semchunk. Let’s say that you have a Pandas dataframe df with a column named content that contains the text entries:
import semchunk
# load the dataframe
df = ...
First, we’ll initialize a chunker object with the same language model as before and the desired chunk size.
chunker = semchunk.chunkerify(
"sentence-transformers/msmarco-distilbert-base-tas-b", chunk_size=512
)
Next, we’ll apply the chunker to the content column of the dataframe. This will result in a list of chunks for each text entry.
df["chunk"] = df["content"].map(chunker)
Finally, we’ll “explode” the chunk column. This means that each element of the list will become a separate row, and the other column values will be replicated.
df = df.explode("chunk")
Lexical search
Lexical search, on the other hand, is a more traditional approach that relies on exact keyword matching. It can be very fast and efficient, but may not always deliver the most relevant or accurate results, particularly for complex or ambiguous queries.
Here is a brief description of sparse retrievers by Isabelle Nguyen [3]:
Sparse retrievers produce vectors whose length equals the size of the vocabulary. Because every document in the corpus only contains a fraction of all the words in the corpus, these vectors are typically sparse: long, with many zeroes, and only few non-zero values. The sparse retrieval algorithm most commonly used today is BM25, an improved version of the classic Tf-Idf.
Here is a short introduction to the BM25 retrieval algorithm from the wikipedia page:
BM25 is a bag-of-words retrieval function that ranks a set of documents based on the query terms appearing in each document, regardless of their proximity within the document.
We are going to use the full text search extension of DuckDB. The retrieval function is the BM25 macro. As mentioned by James Briggs in this article [4] there are other fancier sparse search methods, such as SPLADE.
Fused score
As advised by Sebastian Bruch et al. in [1], we use a convex combination to fuse both scores:
\[s_{\mbox{hybrid}} = \alpha \tilde{s}_{\mbox{semantic}} + (1-\alpha) \tilde{s}_{\mbox{lexical}}\]where:
- $s_{\mbox{hybrid}}$ is the hybrid score,
- $\tilde{s}_{\mbox{semantic}}$ the normalized semantic search score, and
- $\tilde{s}_{\mbox{lexical}}$ the normalized lexical search score.
- $\alpha$ is a constant parameter between 0 and 1.
The normalization of the scores is an important part since it ensures that we combine scores with values between 0 and 1. The theoretical min-max scaling $\Phi_{\mbox{TMM}}$ is used:
\[\tilde{s} = \Phi_{\mbox{TMM}}(s) = \frac{s - m_t}{M-m_t}\]where:
- $s$ is the score function,
- $m_t$ is the theoretical minimum of $s$ (-1 for the semantic score, 0 for the lexical search),
- $M$ is the maximum value of $s$ returned for the current query over all the documents.
This normalization process is tricky for the lexical score, since the score range may vary a lot… Here is a mention of this challenge by Quentin Herreros and Thomas Veasey in [5]
Normalization is essential for comparing scores between different data sets and models, as scores can vary a lot without it. It is not always easy to do, especially for Okapi BM25, where the range of scores is unknown until queries are made. Dense model scores are easier to normalize, as their vectors can be normalized. However, it is worth noting that some dense models are trained without normalization and may perform better with dot products.
However, as described in [1], the normalization function described above seems to give satisfying results. An alternative to this convex combination with theoretical minimum-maximum normalization (TM2C2) would be Reciprocal Rank Fusion (RRF) [6], but the former method appears to be more robust. Here is an except from the conclusion from Sebastian Bruch et al. [1] :
We found that RRF is sensitive to its parameters. We also observed empirically that convex combination of normalized scores outperforms RRF on in-domain and out-of-domain datasets […].
We believe that a convex combination with theoretical minimum-maximum normalization (TM2C2) indeed enjoys properties that are important in a fusion function. Its parameter, too, can be tuned sample-efficiently or set to a reasonable value based on domain knowledge.
The Dataset
We use the dbpedia_14 dataset from Hugging Face. Here is the model card from Hugging Face:
The dataset has a total number of rows of 630000 and the total size of the files is 119 MB. Here is a brief description of the dataset from the Hugging Face dataset page:
The DBpedia ontology classification dataset is constructed by picking 14 non-overlapping classes from DBpedia 2014. They are listed in classes.txt. From each of thse 14 ontology classes, we randomly choose 40,000 training samples and 5,000 testing samples. Therefore, the total size of the training dataset is 560,000 and testing dataset 70,000. There are 3 columns in the dataset (same for train and test splits), corresponding to class index (1 to 14), title and content.
We access the dataset using the datasets library by Hugging Face.
import re
from datasets import load_dataset
import pandas as pd
dataset = load_dataset(path="fancyzhx/dbpedia_14")
train_df = dataset["train"].to_pandas()
train_df["split"] = "train"
print(f"train_df.shape : {train_df.shape}")
train_df.shape : (560000, 4)
test_df = dataset["test"].to_pandas()
test_df["split"] = "test"
print(f"test_df.shape : {test_df.shape}")
test_df.shape : (70000, 4)
df = pd.concat((train_df, test_df), axis=0)
print(df.head())
label title content split
0 0 E. D. Abbott Ltd Abbott of Farnham E D Abbott Limited was a Br... train
1 0 Schwan-Stabilo Schwan-STABILO is a German maker of pens for ... train
2 0 Q-workshop Q-workshop is a Polish company located in Poz... train
3 0 Marvell Software Solutions Israel Marvell Software Solutions Israel known as RA... train
4 0 Bergan Mercy Medical Center Bergan Mercy Medical Center is a hospital loc... train
In our tests, we are not going to use the label and title columns and perform the search on the content column. Let’s look at the distribution of the number of words in this column:
df["content_word_count"] = df["content"].map(
lambda s: len(re.sub(r"\s+", " ", s.strip()).split(" "))
)
print(df.content_word_count.describe())
count 630000.000000
mean 46.134148
std 22.457486
min 1.000000
25% 27.000000
50% 46.000000
75% 65.000000
max 1484.000000
Name: content_word_count, dtype: float64
So we observe that most of the text content is relatively short except for a few entries. Most of the time, the content is already below the input size of the model. In fact, only 76 new text chunks were created by the splits over 600,000 entries. The maximum number of chunks for a single text entry was 8.
Note that we could have directly queried the dataset hosted by Hugging Face from DuckDB using the httpfs extension. See this post more more details : Access 150k+ Datasets from Hugging Face with DuckDB.
import duckdb
con = duckdb.connect()
con.sql("INSTALL httpfs;")
con.sql("LOAD httpfs;")
query = """
SELECT *
FROM 'hf://datasets/fancyzhx/dbpedia_14/dbpedia_14/train-00000-of-00001.parquet';"""
train_df = con.sql(query).df()
train_df["split"] = "train"
print(f"train_df.shape : {train_df.shape}")
con.close()
train_df.shape : (560000, 4)
Implementation with DuckDB
Versions
We are operating on Python version 3.11.8 and running on a Linux x86_64 machine.
numpy : 1.26.4
sentence_transformers : 3.0.0
semchunk : 0.3.1
datasets : 2.19.1
pandas : 2.2.0
duckdb : 0.10.3
pynput : 1.7.7
Load and process the dataset
import warnings
DUCKDB_FILE_PATH = "dbpedia_14.duckdb"
MODEL_NAME = "msmarco-distilbert-base-tas-b"
CHUNK_SIZE = 512 # maximum number of tokens a chunk may contain
def calculate_word_count(s):
"""Calulate the approximate word count in a given string by splitting text
by whitespaces.
"""
return len(re.sub(r"\s+", " ", s.strip()).split(" "))
def load_and_process_dbpedia_14(duckdb_file_path: str) -> None:
con = duckdb.connect(duckdb_file_path)
# get data into a dataframe
# -------------------------
dataset = load_dataset(path="fancyzhx/dbpedia_14")
train_df = dataset["train"].to_pandas()
train_df["split"] = "train"
test_df = dataset["test"].to_pandas()
test_df["split"] = "test"
df = pd.concat((train_df, test_df), axis=0)
df["content_word_count"] = df["content"].map(calculate_word_count)
# split the text to satisfy max token length
# ------------------------------------------
with warnings.catch_warnings():
warnings.simplefilter(
action="ignore",
)
chunker = semchunk.chunkerify(
f"sentence-transformers/{MODEL_NAME}", chunk_size=CHUNK_SIZE
)
df["chunk"] = df["content"].map(chunker)
df["content_n_chunks"] = df["chunk"].map(len)
df = df.explode("chunk")
df = df.reset_index(drop=True)
df["chunk_index"] = df.index
df["chunk_word_count"] = df["chunk"].map(calculate_word_count)
# create the table and load the data
# ----------------------------------
query = "DROP TABLE IF EXISTS dbpedia_14"
con.execute(query)
query = "CREATE TABLE dbpedia_14 AS (SELECT * FROM df)"
con.execute(query)
query = "SELECT chunk_index, title, chunk FROM dbpedia_14 LIMIT 10"
con.sql(query).show()
con.close()
load_and_process_dbpedia_14(DUCKDB_FILE_PATH)
┌─────────────┬──────────────────────┬──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ chunk_index │ title │ chunk │
│ int64 │ varchar │ varchar │
├─────────────┼──────────────────────┼──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ 0 │ E. D. Abbott Ltd │ Abbott of Farnham E D Abbott Limited was a British coachbuilding business based in Farnham Surrey trading under that name fro… │
│ 1 │ Schwan-Stabilo │ Schwan-STABILO is a German maker of pens for writing colouring and cosmetics as well as markers and highlighters for office u… │
│ 2 │ Q-workshop │ Q-workshop is a Polish company located in Poznań that specializes in designand production of polyhedral dice and dice accesso… │
│ 3 │ Marvell Software S… │ Marvell Software Solutions Israel known as RADLAN Computer Communications Limited before 2007 is a wholly owned subsidiary of… │
│ 4 │ Bergan Mercy Medic… │ Bergan Mercy Medical Center is a hospital located in Omaha Nebraska. It is part of the Alegent Health System. │
│ 5 │ The Unsigned Guide │ The Unsigned Guide is an online contacts directory and careers guide for the UK music industry. Founded in 2003 and first pub… │
│ 6 │ Rest of the world │ Within sports and games played at the international competitive level the Rest of the World refers to a team of players from … │
│ 7 │ Globoforce │ Globoforce is a multinational company co-headquartered in Southborough Massachusetts and Dublin Ireland providing cloud-based… │
│ 8 │ Rompetrol │ The Rompetrol Group N.V. is a Romanian oil company that operates in many countries throughout Europe. The group is active pri… │
│ 9 │ Wave Accounting │ Wave is the brand name for a suite of online small business software products. The legal company name is Wave Accounting Inc.… │
├─────────────┴──────────────────────┴──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ 10 rows 3 columns │
└───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
Create the embeddings
EMBEDDING_DIMENSION = 768
con = duckdb.connect(DUCKDB_FILE_PATH)
# create vector column
query = f"""ALTER TABLE dbpedia_14
ADD COLUMN IF NOT EXISTS chunk_embedding FLOAT[{EMBEDDING_DIMENSION}]"""
con.execute(query)
# create embeddings
embedding_model = SentenceTransformer(MODEL_NAME)
query = "SELECT chunk_index, chunk FROM dbpedia_14"
chunks_df = con.sql(query).df()
n_chunks = chunks_df.shape[0]
print(f"Embedding {n_chunks} text chunks")
for row in chunks_df.itertuples():
chunk_index = row.chunk_index
chunk = row.chunk
chunk_embedding = embedding_model.encode(chunk)
chunk_embedding = ", ".join(f"{num:.8e}" for num in chunk_embedding)
chunk_embedding = f"[{chunk_embedding}]"
query = f"""UPDATE dbpedia_14 SET chunk_embedding = '{chunk_embedding}'
WHERE chunk_index = {chunk_index}"""
con.execute(query)
if chunk_index % 1000 == 0:
print(f"chunk #{chunk_index:10d} / {n_chunks}")
print("Embedding done")
query = "SELECT chunk_index, title, chunk_embedding FROM dbpedia_14 LIMIT 10"
con.sql(query).show()
con.close()
┌─────────────┬──────────────────────┬──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ chunk_index │ title │ chunk_embedding │
│ int64 │ varchar │ float[768] │
├─────────────┼──────────────────────┼──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ 0 │ E. D. Abbott Ltd │ [-0.056666914, 0.015233386, -0.17769384, 0.12177265, -0.27672547, 0.046277814, 0.39038557, -0.3147704, 0.24360661, 0.07252333,… │
│ 1 │ Schwan-Stabilo │ [-0.14498723, -0.2679027, 0.123010844, -0.39085975, -0.12855297, 0.30463976, -0.105671585, 0.27722526, 0.018881973, -0.1282772… │
│ 2 │ Q-workshop │ [0.13676694, 0.098195106, -0.053731065, 0.0071483315, 0.070571125, 0.36510956, -0.04706168, 0.037993953, 0.087918885, 0.029945… │
│ 3 │ Marvell Software S… │ [-0.050261598, 0.18375121, -0.10736598, -0.2948784, -0.15807082, 0.034029845, -0.08561164, 0.14915323, 0.2591469, -0.38054726,… │
│ 4 │ Bergan Mercy Medic… │ [0.008181838, 0.16176185, 0.04924671, -0.46889335, 0.00013711391, 0.23793076, 0.39932668, 0.15312782, 0.18730867, -0.6077049, … │
│ 5 │ The Unsigned Guide │ [0.36607465, -0.12668529, 0.26784873, -0.16516903, -0.15815514, -0.0043638134, 0.09445748, -0.17474835, 0.09283422, 0.2428908,… │
│ 6 │ Rest of the world │ [-0.23604554, -0.06427196, 0.0075137517, -0.03382628, -0.31959048, -0.13400583, -0.11378659, 0.29048055, -0.3271433, -0.012481… │
│ 7 │ Globoforce │ [-0.31952775, 0.18657476, 0.6452048, -0.23438886, -0.23444332, 0.15517722, 0.31093433, 0.029395044, -0.13205208, -0.22595386, … │
│ 8 │ Rompetrol │ [0.010033048, 0.10094921, 0.029594878, -0.031000847, 0.043723732, 0.06178601, -0.4039024, 0.37023473, -0.18508624, 0.14265403,… │
│ 9 │ Wave Accounting │ [0.087288335, -0.116302095, 0.11574627, 0.04099939, -0.0098696835, 0.093530245, -0.23412664, 0.21668597, -0.35045913, 0.003505… │
├─────────────┴──────────────────────┴──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ 10 rows 3 columns │
└───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
This step is rather long. It may take more than an hour on a CPU… Note that is possible to perform it on multiple CPUs or GPUs with start_multi_process_pool. Also, we could bulk update by creating another table with all the embeddings and merge.
We can now perform a semantic search with the following function:
from typing import List
def query_embeddings(
duckdb_file_path: str,
model_name: str,
embedding_dimension: int,
search_txt: str,
result_count: int = 3,
table_name: str = "dbpedia_14",
embedding_column: str = "chunk_embedding",
columns: List[str] = ["chunk_index", "title", "content"],
) -> None:
con = duckdb.connect(duckdb_file_path)
# Get the embedding of the search query
model = SentenceTransformer(model_name)
search_embedding = model.encode(search_txt)
search_embedding = ", ".join(f"{num:.8e}" for num in search_embedding)
search_embedding = f"[{search_embedding}]"
# query the vectorstore
query = f"""
SELECT {', '.join(columns)}, array_cosine_similarity(
{embedding_column},
{search_embedding}::FLOAT[{embedding_dimension}])
AS cosine_similarity
FROM {table_name}
ORDER BY cosine_similarity DESC
LIMIT {result_count};"""
con.sql(query).show()
con.close()
search_txt = "what is the fastest car"
query_embeddings(DUCKDB_FILE_PATH, MODEL_NAME, EMBEDDING_DIMENSION, search_txt)
┌─────────────┬──────────────┬──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┬───────────────────┐
│ chunk_index │ title │ content │ cosine_similarity │
│ int64 │ varchar │ varchar │ float │
├─────────────┼──────────────┼──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┼───────────────────┤
│ 237184 │ SSC Aero │ The SSC Aero is an American-built mid-engine sports car by SSC North America (formerly known as Shelby SuperCars)… │ 0.8467013 │
│ 212102 │ Jaguar XJ220 │ The Jaguar XJ220 is a two-seater supercar produced by British luxury car manufacturer Jaguar from 1992 until 1994… │ 0.84581566 │
│ 238475 │ BMW M5 │ The BMW M5 is a high performance version of the BMW 5-Series executive car built by the Motorsport division of BM… │ 0.8393138 │
└─────────────┴──────────────┴──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┴───────────────────┘
In this particular case, we did not create an index to speed up the semantic search. This is because the number of entries is less than one million, and the search time is already quite fast, at just a few tenths of a second.
However, if you’re working with a larger dataset or need even faster search times, you could consider using an HNSW (Hierarchical Navigable Small Worlds) index. This type of index is available in the vss extension for DuckDB.
Create Full Text Search index
con = duckdb.connect(DUCKDB_FILE_PATH)
con.sql("INSTALL fts;")
con.sql("LOAD fts;")
query = """PRAGMA create_fts_index('dbpedia_14', 'chunk_index', 'chunk',
stemmer = 'english', stopwords = 'english', ignore = '(\\.|[^a-z])+',
strip_accents = 1, lower = 1, overwrite = 0);"""
con.execute(query)
con.close()
The index creation takes a few seconds for the 600000 entries of the dataset. We can now perform a lexical search with this function:
def full_text_search(
duckdb_file_path: str,
search_txt: str,
result_count: int = 3,
table_name: str = "dbpedia_14",
document_identifier: str = "chunk_index",
columns: List[str] = ["title", "content", "chunk_index"],
):
"""
Query the DuckDB database for the most relevant chunks of text based on
the sparse search query.
"""
if document_identifier not in columns:
columns.append(document_identifier)
con = duckdb.connect(duckdb_file_path)
query = f"""
SELECT {', '.join(columns)}, bm25_score
FROM (
SELECT *, fts_main_{table_name}.match_bm25(
{document_identifier},
'{search_txt}',
fields := 'chunk'
) AS bm25_score
FROM {table_name}
) sq
WHERE bm25_score IS NOT NULL
ORDER BY bm25_score DESC
LIMIT {result_count};"""
con.sql(query).show()
con.close()
search_txt = "isaac asimov"
full_text_search(DUCKDB_FILE_PATH, search_txt)
┌──────────────────────┬─────────────────────────────────────────────────────────────────────────────────────────────────────────────┬─────────────┬────────────────────┐
│ title │ content │ chunk_index │ bm25_score │
│ varchar │ varchar │ int64 │ double │
├──────────────────────┼─────────────────────────────────────────────────────────────────────────────────────────────────────────────┼─────────────┼────────────────────┤
│ Isaac Asimov's Rob… │ Isaac Asimov's Robot City: Suspicion is a book written in 1987 by Mike McQuay. It is part of the series … │ 523014 │ 10.51863443679827 │
│ Isaac Asimov's Rob… │ Isaac Asimov's Robot City: Perihelion is a book written in 1988 by William F. Wu. It is part of the seri… │ 547741 │ 10.51863443679827 │
│ The Best Mysteries… │ The Best Mysteries of Isaac Asimov is a collection of mystery short stories by American author Isaac Asi… │ 523245 │ 10.449336866789256 │
└──────────────────────┴─────────────────────────────────────────────────────────────────────────────────────────────────────────────┴─────────────┴────────────────────┘
Hybrid search
We now combine both approaches in a single function for hybrid search. The function first gets the dense vector representation of the query using the embedding model, and then performs a semantic search by querying the vectorstore using the cosine similarity between the query vector and the dense vector representations stored in the embedding_column. The results are sorted by cosine similarity in descending order and limited to k_dense=100 results. The function then proceeds to the lexical search by querying the full-text search index using the BM25 similarity between the query text and the documents stored in the table. The results are sorted by BM25 similarity in descending order and limited to k_sparse=100 results.
The final scores are sorted in descending order and limited to n_results=5 results. By default we use a convex combination parameter $\alpha=0.8$.
from time import perf_counter
def query_hybrid(
duckdb_file_path: str,
embedding_model,
embedding_dimension: int,
search_txt: str,
table_name: str = "dbpedia_14",
embedding_column: str = "chunk_embedding",
document_identifier: str = "chunk_index",
columns: List[str] = ["chunk_index", "title", "content", "label"],
k_dense: int = 100,
k_sparse: int = 100,
alpha: float = 0.8,
n_results: int = 5,
) -> pd.DataFrame:
inf_sem_score = -1.0
inf_lex_score = 0.0
with duckdb.connect(duckdb_file_path) as con:
if document_identifier not in columns:
columns.append(document_identifier)
# semantic search
# ---------------
# Get the embedding of the search query
search_emb = embedding_model.encode(search_txt)
search_emb_str = ", ".join(f"{num:.8e}" for num in search_emb)
search_emb_str = f"[{search_emb_str}]"
# query the vectorstore
query = f"""
SELECT {', '.join(columns)}, array_cosine_similarity({embedding_column},
{search_emb_str}::FLOAT[{embedding_dimension}]) AS sem_sc
FROM {table_name}
ORDER BY sem_sc DESC LIMIT {k_dense};"""
start = perf_counter()
df_dense = con.sql(query).df()
sem_search_elapsed_time_s = perf_counter() - start
# normalization
score_sem_max = df_dense["sem_sc"].max()
df_dense["sem_sc_n"] = (df_dense["sem_sc"] - inf_sem_score) / (
score_sem_max - inf_sem_score
)
# lexical search
# --------------
query = f"""
SELECT {', '.join(columns)}, fts_main_{table_name}.match_bm25(
{document_identifier}, '{search_txt}') AS lex_sc
FROM {table_name}
ORDER BY lex_sc DESC LIMIT {k_sparse};"""
start = perf_counter()
df_sparse = con.sql(query).df()
lex_search_elapsed_time_s = perf_counter() - start
print(
"sem/lex search elapsed time : "
+ f"{sem_search_elapsed_time_s:.4f}/{lex_search_elapsed_time_s:.4f} s"
)
# normalization
score_lex_max = df_sparse["lex_sc"].max()
df_sparse["lex_sc_n"] = (df_sparse["lex_sc"] - inf_lex_score) / (
score_lex_max - inf_lex_score
)
# convex combination
# ------------------
df = pd.merge(
df_dense[[document_identifier, "sem_sc", "sem_sc_n"]],
df_sparse[[document_identifier, "lex_sc", "lex_sc_n"]],
on=document_identifier,
how="outer",
)
df = df.fillna(0.0)
df["convex_sc"] = alpha * df.sem_sc_n + (1.0 - alpha) * df.lex_sc_n
df = df.sort_values(by="convex_sc", ascending=False).head(n_results)
df = pd.merge(df, df_dense[columns], on=document_identifier, how="left")
df.set_index(document_identifier)
df_b = df_sparse[columns]
df_b = df_b.set_index(document_identifier)
df = df.fillna(df_b)
df = df.reset_index(drop=True)
return df
The following scores are computed:
sem_sc: semantic scoresem_sc_n: normalized semantic scorelex_sc: lexical scorelex_sc_n: normalized lexical scoreconvex_sc: convex/hybrid score
We also included in this function some timing measures of the semantic and lexical searches. The hybrid search function can be called in an interactive manner using the following piece of code:
from pynput import keyboard
LABELS = {
0: "Company",
1: "EducationalInstitution",
2: "Artist",
3: "Athlete",
4: "OfficeHolder",
5: "MeanOfTransportation",
6: "Building",
7: "NaturalPlace",
8: "Village",
9: "Animal",
10: "Plant",
11: "Album ",
12: "Film",
13: "WrittenWork",
}
QUESTION = (
"Enter your search query (or type 'ESC' to exit) and then press 'RETURN': "
)
# Start listening for keyboard events
listener = keyboard.Listener(on_press=on_press)
listener.start()
while True:
print(QUESTION)
search = input()
# Check if the user pressed the Escape key
if not listener.running:
break
answer_df = query_hybrid(
duckdb_file_path=DUCKDB_FILE_PATH,
embedding_model=model,
embedding_dimension=EMBEDDING_DIMENSION,
search_txt=search,
)
answer_df.label = answer_df.label.replace(LABELS)
print(answer_df.head(N_RESULTS))
Example results
In the following examples, we also included the content of the best matching entry after displaying the ranking with the five best results.
Enter your search query (or type 'ESC' to exit) and then press 'RETURN':
citroen C5
sem/lex search elapsed time : 0.7070/0.1034 s
chunk_index sem_sc sem_sc_n lex_sc lex_sc_n convex_sc title content label
0 225646 0.895 1.000 6.427 0.936 0.987 Citroën C5 The Citroën C5 is a ... MeanOfTransportation
1 205316 0.885 0.995 6.298 0.917 0.979 Citroën C6 The Citroën C6 is an... MeanOfTransportation
2 208890 0.844 0.973 6.796 0.989 0.976 Citroën C2 The Citroën C2 was a... MeanOfTransportation
3 230100 0.876 0.990 6.257 0.911 0.974 Citroën C4 The Citroën C4 is a ... MeanOfTransportation
4 206331 0.844 0.973 6.369 0.927 0.964 Citroën CX The Citroën CX is an... MeanOfTransportation
The Citroën C5 is a large family car produced by the French manufacturer Citroën since early 2001 and now in its second generation. The C5 replaced the Citroën Xantia in the large family car class.
Enter your search query (or type 'ESC' to exit) and then press 'RETURN':
Python programming
sem/lex search elapsed time : 0.5871/0.1001 s
chunk_index sem_sc sem_sc_n lex_sc lex_sc_n convex_sc title content label
0 557852 0.859 1.000 9.519 1.000 1.000 Learning Python Learning Python is a... WrittenWork
1 546640 0.851 0.996 9.084 0.954 0.987 Core Python Programming Core Python Programm... WrittenWork
2 373646 0.766 0.950 7.348 0.772 0.914 Python curtus breiten... Common names: Borneo... Animal
3 369857 0.773 0.953 6.824 0.717 0.906 Python timoriensis Common names: Timor ... Animal
4 375975 0.768 0.951 6.778 0.712 0.903 Children's python Children's python (A... Animal
Learning Python is a tutorial book for the Python programming language and is published by O'Reilly.
Enter your search query (or type 'ESC' to exit) and then press 'RETURN':
most venomous snakes
sem/lex search elapsed time : 0.5777/0.0973 s
chunk_index sem_sc sem_sc_n lex_sc lex_sc_n convex_sc title content label
0 399609 0.824 0.997 8.936 0.983 0.994 Chilorhinophis Common name: two-hea... Animal
1 399963 0.814 0.991 9.089 1.000 0.993 Chilorhinophis carpen... Chilorhinophis carpe... Animal
2 366450 0.812 0.990 8.789 0.967 0.986 Hydrophis klossi Hydrophis klossi com... Animal
3 609929 0.809 0.989 8.789 0.967 0.984 Hydrophis inornatus Hydrophis inornatus ... Animal
4 389393 0.796 0.982 8.934 0.983 0.982 Grass snake The grass snake (Nat... Animal
Common name: two-headed snakes.Chilorhinophis is a genus of venomous snakes found in Africa. Currently three species are recognized.
Enter your search query (or type 'ESC' to exit) and then press 'RETURN':
tallest cathedral
sem/lex search elapsed time : 0.5819/0.0949 s
chunk_index sem_sc sem_sc_n lex_sc lex_sc_n convex_sc title content label
0 590328 0.864 1.000 6.524 0.942 0.988 Lincoln Cathedral Lincoln Cathedral (i... Building
1 259562 0.854 0.994 6.550 0.946 0.985 St Martin's Cathedral... St Martin's Cathedra... Building
2 243677 0.815 0.973 6.922 1.000 0.979 Ivan the Great Bell T... The Ivan the Great B... Building
3 592368 0.841 0.988 6.097 0.881 0.966 Dom Tower of Utrecht The Dom Tower (Cathe... Building
4 265368 0.816 0.974 6.158 0.890 0.957 Immaculate Heart of M... The Immaculate Heart... Building
Lincoln Cathedral (in full The Cathedral Church of the Blessed Virgin Mary of Lincoln or sometimes St. Mary's Cathedral) is a cathedral located in Lincoln in England and seat of the Bishop of Lincoln in the Church of England. Building commenced in 1088 and continued in several phases throughout the medieval period. It was reputedly the tallest building in the world for 238 years (1311–1549). The central spire collapsed in 1549 and was not rebuilt.
Enter your search query (or type 'ESC' to exit) and then press 'RETURN':
famous french movie from the 1990s
sem/lex search elapsed time : 0.5715/0.1181 s
chunk_index sem_sc sem_sc_n lex_sc lex_sc_n convex_sc title content label
0 502559 0.815 0.987 5.160 0.823 0.954 Bernie (1996 film) Bernie is a 1996 mov... Film
1 512119 0.817 0.988 4.539 0.724 0.935 American Cuisine (film) American Cuisine (Cu... Film
2 503959 0.814 0.986 4.519 0.720 0.933 Le Péril jeune Le péril jeune (Fren... Film
3 488187 0.839 1.000 0.000 0.000 0.800 A French Woman A French Woman (Fren... Film
4 508206 0.832 0.996 0.000 0.000 0.797 Paris 1900 (film) Paris 1900 is a 1947... Film
Bernie is a 1996 movie from French director and actor Albert Dupontel.
Let’s see an example where the search is not working so well:
Enter your search query (or type 'ESC' to exit) and then press 'RETURN':
citron C5
sem/lex search elapsed time : 0.5780/0.1205 s
chunk_index sem_sc sem_sc_n lex_sc lex_sc_n convex_sc title content label
0 409053 0.792 0.964 8.018 1.000 0.971 Balady citron Balady citron (Arabi... Plant
1 413907 0.813 0.975 6.409 0.799 0.940 Florentine citron The citron of Floren... Plant
2 436610 0.792 0.964 6.518 0.813 0.934 Diamante citron The Diamante citron ... Plant
3 614885 0.809 0.973 4.300 0.536 0.886 Citron The citron is a frag... Plant
4 225646 0.859 1.000 0.000 0.000 0.800 Citroën C5 The Citroën C5 is a ... MeanOfTransportation
Balady citron (Arabic: أترج بلدي) or Palestinian citron (Hebrew: הָאֶתְרוֹג הַפַּלֶשְׂתִּינִי) is a variety of citron or etrog grown in Israel for Jewish ritual purposes.
We made a mistake in the search query by typing “citron” instead of “citroen” or “citroën”. Despite the error, the semantic search was able to correctly identify the Citroën C5 as the most relevant result, with the highest semantic score. However, the lexical search returned a score of 0 for this entry and a score of 1 for a “citron” lemon fruit entry, which ended up being the top result with the combined score. To prevent this kind of situation, we could maybe consider imposing a minimum threshold for the normalized semantic score.
Final remarks
-
The quality of the search results is really difficult to evaluate since we did not use any retrieval validation dataset, to compare the results against. The convex combination method with theoretical minimum-maximum normalization appears to produce accurate and relevant matching results, based on our preliminary testing and analysis.
-
The chosen hybrid search method is straightforward to implement with DuckDB and sentence_transformers, to create an on-premise information retrieval prototype. It can be a good starting point for exploring more information retrieval techniques. Hugging Faces is such a great asset for anyone interested in natural language processing.
References
[1] Sebastian Bruch, Siyu Gai, and Amir Ingber. 2023. An Analysis of Fusion Functions for Hybrid Retrieval. ACM Trans. Inf. Syst. 42, 1, Article 20 (January 2024), 35 pages. https://doi.org/10.1145/3596512
[2] Seo Jaehyung, Taemin Lee, Hyeonseok Moon, Chanjun Park, Sugyeong Eo, Imatitikua D. Aiyanyo, Kinam Park, Aram So, Sungmin Ahn, and Jeongbae Park. 2022. Dense-to-Question and Sparse-to-Answer: Hybrid Retriever System for Industrial Frequently Asked Questions, Mathematics 10, no. 8: 1335. https://doi.org/10.3390/math10081335
[3] Isabelle Nguyen - Hybrid Document Retrieval https://haystack.deepset.ai/blog/hybrid-retrieval
[4] James Briggs - Getting Started with Hybrid Search https://www.pinecone.io/learn/hybrid-search-intro/
[5] Quentin Herreros, Thomas Veasey - Improving information retrieval in the Elastic Stack: Hybrid retrieval, https://www.elastic.co/blog/improving-information-retrieval-elastic-stack-hybrid
[6] Gordon V. Cormack, Charles L A Clarke, and Stefan Buettcher. 2009. Reciprocal rank fusion outperforms condorcet and individual rank learning methods. In Proceedings of the 32nd international ACM SIGIR conference on Research and development in information retrieval (SIGIR ‘09). Association for Computing Machinery, New York, NY, USA, 758–759. https://doi.org/10.1145/1571941.1572114