German-style strings in Apache Arrow WIP
Version 1.4 of the Apache Arrow Columnar Format introduced the Variable-size Binary View Layout, a new physical representation for variable-length values. It is exposed as two logical types, BinaryView for raw bytes and StringView for UTF-8 strings, mirroring the existing Binary / String pair: same memory layout, the string flavor adds the UTF-8 validity contract on the value bytes. The name view reflects how each value is represented: a fixed-size 16-byte descriptor that either holds short values inline or points to long ones in a separate buffer. The descriptor is the handle, the storage is separate; operations move the views, the underlying bytes stay put, and several views can refer to the same byte range. The format is at version 1.5 today.
The layout is Arrow’s adaptation of the German-style string described in the Umbra paper by Neumann and Freitag [2], already in use by Velox and DuckDB. For long strings, the view also carries a 4-byte prefix copied from the value, so that most comparisons short-circuit without an indirection into the value buffer. I first read about this layout in Topol’s In-Memory Analytics with Apache Arrow [1] (figures 1.10 and 1.11), a book I have enjoyed a lot.
The classic variable-length layout
Arrow’s pre-existing String/Binary type stores a variable-length sequence in three buffers: a validity bitmap, an offsets buffer of n + 1 signed int32 values, and a single contiguous values buffer. Value i is the byte range [offsets[i], offsets[i + 1]) of the values buffer, and the offsets are monotonically non-decreasing.
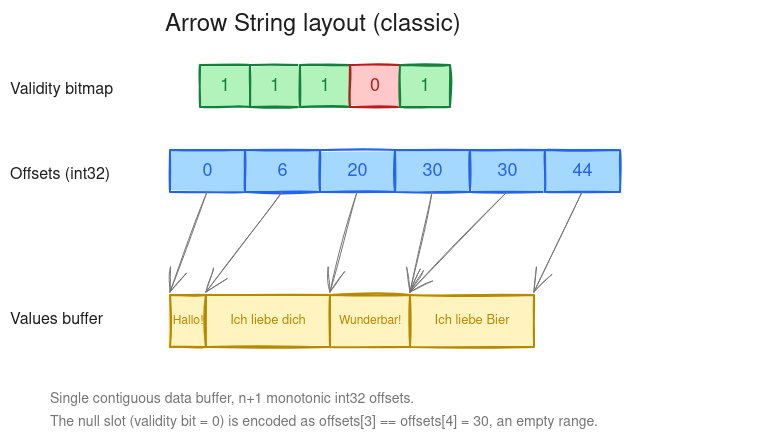
Random access is O(1), but every value lives at exactly one offset in one buffer; slicing or sorting cannot avoid rewriting at least the offsets buffer.
The view header
In a StringView array, the offsets buffer is gone. Each value is represented by a fixed-size 16-byte structure called a view header. The first 4 bytes always hold the length. If the length is at most 12, the remaining 12 bytes hold the value inline. If the length exceeds 12, the value lives outside the header and the remaining 12 bytes hold three fields: a 4-byte prefix copied from the start of the value, the index of the value buffer the value lives in, and the offset within that buffer.
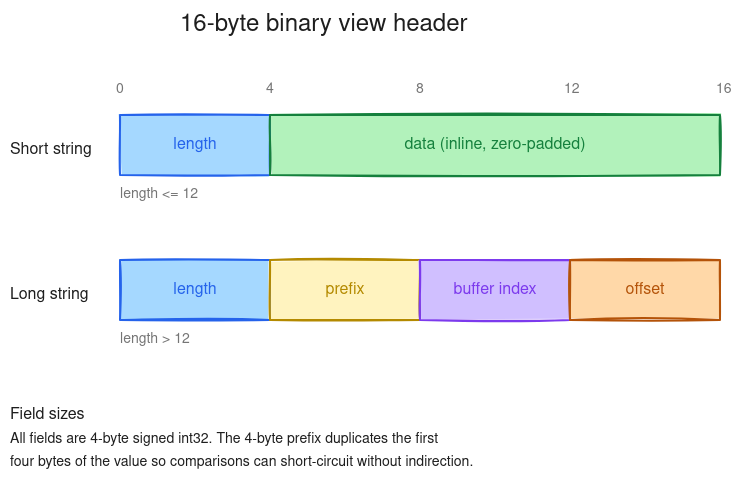
Short strings (length ≤ 12) carry their bytes in the header; long strings carry a 4-byte prefix and a (buffer, offset) pair pointing into a value buffer.
The length, buffer index, and offset are signed 32-bit integers; the prefix is 4 raw bytes copied from the start of the value. Arrow uses signed integers for indices throughout the format because some languages, notably Java, lack unsigned integer types. This equality is a validity invariant the prefix-equality fast path below relies on: a long view whose prefix disagrees with its value bytes is a corrupt array.
Multiple value buffers
Unlike every other Arrow layout, the view layout allows a variable number of buffers per array. After the validity bitmap and the views buffer, an implementation can attach zero or more value buffers; each long view names the value buffer it points to by index. The buffers may be of any size, and the same byte range can be referenced by several views, in any order.
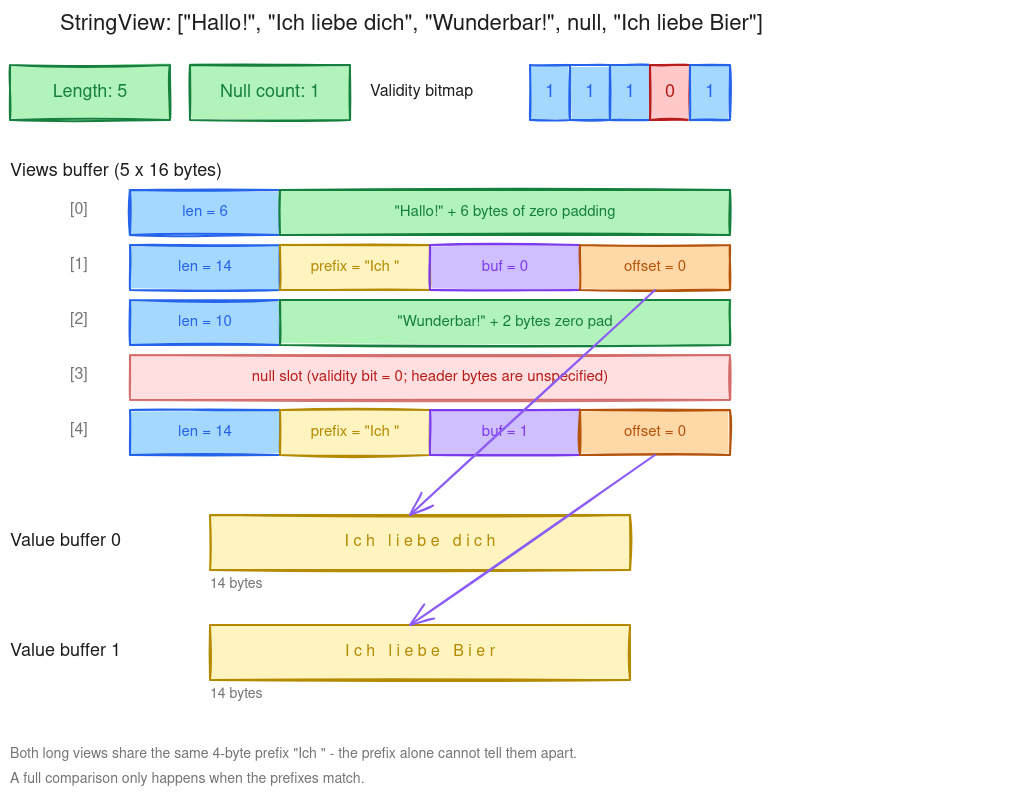
The two long views [1] and [4] point into separate value buffers and share the same 4-byte prefix Ich .
This layout has three practical consequences. First, the views buffer can be reordered, sliced, or filtered without touching any value bytes; only the 16-byte headers move. Sorts and selection filters rewrite the views buffer but leave the value buffers untouched, referenced as-is. Concatenating two arrays is similarly cheap: keep both sets of value buffers as-is, concatenate the views buffers, and shift the buffer indices of the second array’s long views by the buffer count of the first. The string bytes are never copied.
Second, the inline 4-byte prefix turns the common case of string inequality into a single cache-resident comparison. If two prefixes differ, the strings differ, and the indirection into the value buffer is skipped. The reverse direction does not hold: equal prefixes do not imply equal strings. The strings "Ich liebe dich" and "Ich liebe Bier" share the prefix Ich , so the prefix check passes and the full value bytes still need to be read for any actual comparison. The prefix is a one-way short-circuit: cheap when it rules a comparison out, no help when it does not.
Third, when an array’s strings are mostly short (length ≤ 12), every value lives inside its view header and no pointer chasing into a value buffer is needed. The views buffer is contiguous and read linearly; the indirection only kicks in for the long-string minority.
A short PyArrow example
Constructing a StringView array from Python requires pyarrow v14 or newer:
import pyarrow as pa
arr = pa.array(
["Hallo!", "Ich liebe dich", "Wunderbar!", None, "Ich liebe Bier"],
type=pa.string_view(),
)
print(arr.type)
print(arr)
print("nbytes:", arr.nbytes)
string_view
[
"Hallo!",
"Ich liebe dich",
"Wunderbar!",
null,
"Ich liebe Bier"
]
nbytes: 109
The 109 bytes break down as 1 byte of validity bitmap (0b00010111), 80 bytes of views (5 × 16), and 28 bytes of value data. Decoding the views buffer confirms the layout:
| Slot | Length | Storage | Header contents |
|---|---|---|---|
[0] |
6 | inline | "Hallo!" + 6 trailing bytes |
[1] |
14 | out-of-line | prefix "Ich ", buffer 0, offset 0 |
[2] |
10 | inline | "Wunderbar!" + 2 trailing bytes |
[3] |
0 | null slot | header bytes unspecified |
[4] |
14 | out-of-line | prefix "Ich ", buffer 0, offset 14 |
The trailing bytes of short views and the contents of the null slot’s view are left unspecified by the Arrow format; pyarrow zeroes them in practice, but readers must not depend on this. PyArrow has packed the two out-of-line values into a single 28-byte value buffer: "Ich liebe dich" at offset 0, then "Ich liebe Bier" at offset 14. The Arrow spec allows any number of value buffers; the constructor chose one here. The two long views carry the same prefix Ich and the same length 14. Only the trailing 10 bytes differ, which is exactly the case the prefix fast path cannot resolve on its own.
Tradeoffs
The view layout is not strictly better than the classic String type. Long strings carry an extra indirection from the header to the value buffer, and the value buffers can grow fragmented after slices and concatenations: regions reachable from no view are not reclaimed without an explicit compaction pass. The prefix fast path pays off only when prefixes discriminate between values; for arrays of URLs or paths that share a common host, the four inline bytes do no useful work on most comparisons.
Availability
The view type was added to the Arrow Columnar Format in v1.4 (the current version is v1.5) and is supported from Arrow C++ / pyarrow v14 onward. IPC streams and files that contain view arrays are rejected by readers that predate v1.4; the wire format is not backward compatible, so producers writing for older consumers should fall back to the classic String type. The implementation status page tracks support across the other language libraries.
References
- [1] Topol, M. (2024). In-Memory Analytics with Apache Arrow, 2nd edition. Packt Publishing. The chapter “Getting Started with Apache Arrow” describes the variable-length binary view array layout (figures 1.10 and 1.11).
- [2] Neumann, T., and Freitag, M. (2020). Umbra: A Disk-Based System with In-Memory Performance. 10th Annual Conference on Innovative Data Systems Research (CIDR). Section 3.1 introduces the 16-byte string header later adopted by Arrow.
- [3] Apache Arrow project. Variable-size Binary View Layout. Authoritative specification.