Data Loading from S3 Parquet Files to PostgreSQL on OVH Cloud
Introduction
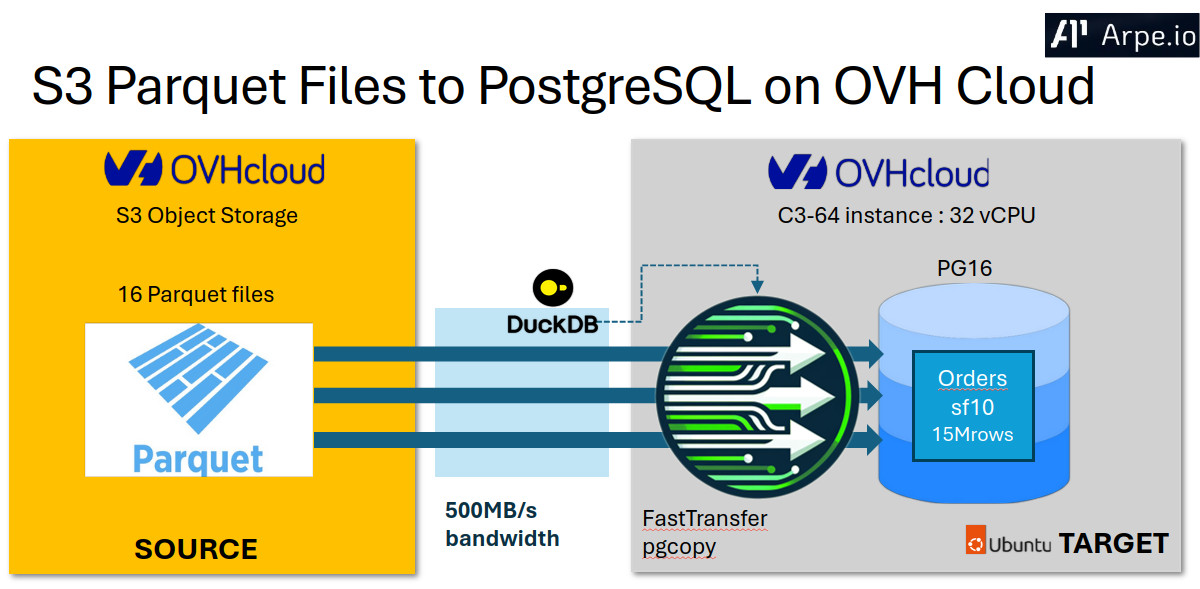
Loading data efficiently from cloud storage into databases remains a critical challenge for data engineers. FastTransfer addresses this challenge through parallel data loading capabilities and flexible configuration options. This post demonstrates FastTransfer’s performance when loading Parquet files from OVH’s S3-compatible object storage into PostgreSQL on OVH public cloud infrastructure.
The Setup: Cloud Infrastructure That Makes Sense
For our testing environment, we deployed PostgreSQL on an OVH c3-64 instance in their Gravelines datacenter. Here’s what we’re working with:
Software Versions
- FastTransfer: Version 0.13.12.0 (X64 architecture, .NET 8.0.20)
- Operating System: Ubuntu 24.04.3 LTS
- Source Engine: DuckDB v1.3.2 (for Parquet reading and streaming)
- Target Database: PostgreSQL 16.10
Hardware Configuration
- Compute: 32 vCores @ 2.3 GHz with 64 GB RAM
- Storage: 400 GB local NVMe where PostgreSQL’s data directory resides
- Network: 4 Gbps bandwidth
- Location: Gravelines (GRA11) datacenter
The local NVMe delivers strong sequential write performance at 1465 MiB/s (measured with fio), providing ample disk bandwidth for our data loading workloads.
This configuration represents a practical mid-range setup, not the smallest instance that would struggle with parallel workloads, nor an oversized machine that would mask performance characteristics.
The Data: TPC-H Orders Table
We’re using the TPC-H benchmark’s orders table at scale factor 10, which gives us:
- 16 Parquet files, evenly distributed at 29.2 MiB each
- Total dataset size: 467.8 MiB
- 15 million rows with mixed data types (integers, decimals, dates, and varchar)
The data resides in an OVH S3-compatible object storage bucket in the Gravelines region, and each file contains roughly 937,500 rows. This distribution allows us to test parallel loading strategies effectively.
FastTransfer in Action: The Command That Does the Heavy Lifting
Here’s the actual command we use to load data:
./FastTransfer \
--sourceconnectiontype "duckdbstream" \
--sourceserver ":memory:" \
--query "SELECT * exclude filename from read_parquet('s3://arpeiofastbcp/tpch/sf10/orders/*.parquet', filename=true) t" \
--targetconnectiontype "pgcopy" \
--targetserver "localhost:5432" \
--targetuser "fasttransfer" \
--targetpassword "********" \
--targetdatabase "tpch" \
--targetschema "tpch_10_test" \
--targettable "orders" \
--method "DataDriven" \
--distributeKeyColumn "filename" \
--datadrivenquery "select file from glob('s3://arpeiofastbcp/tpch/sf10/orders/*.parquet')" \
--loadmode "Truncate" \
--mapmethod "Name" \
--batchsize 10000 \
--degree 16
Let’s break down the key components and understand what each parameter does:
Source Configuration
--sourceconnectiontype "duckdbstream": Uses DuckDB’s memory-efficient streaming connection--sourceserver ":memory:": Runs DuckDB in-memory mode for temporary data processing without persisting to disk--query: The DuckDB SQL that leverages theread_parquet()function to directly access Parquet files from S3, withfilename=trueto capture file origins for distribution
Target Configuration
--targetconnectiontype "pgcopy": Uses PostgreSQL’s native COPY protocol, a fast method for bulk loading data into PostgreSQL--targetserver "localhost:5432": Standard PostgreSQL connection details--targetuserand--targetpassword: Database authentication credentials
Parallelization Strategy
--method "DataDriven": Distributes work based on distinct values in a specified column, in our case each worker processes specific files--distributeKeyColumn "filename": Uses the filename column to assign work to workers, ensuring each file is processed by exactly one worker--datadrivenquery: Overrides the default distinct value selection with an explicit file list usingglob(), giving us precise control over work distribution--degree 16: Creates 16 parallel workers. FastTransfer supports 1-1024 workers, or negative values for CPU-adaptive scaling (e.g.,-2uses half available CPUs)
Loading Configuration
--loadmode "Truncate": Clears the target table before loading, ensuring a clean slate (alternative is"Append"for adding to existing data)--mapmethod "Name": Maps source to target columns by name rather than position, providing flexibility when column orders differ--batchsize 10000: Processes 10,000 rows per bulk copy operation (default is 1,048,576). Smaller batches can reduce memory usage but may impact throughput
About FastTransfer
FastTransfer is designed specifically for efficient data movement between different database systems, particularly excelling with large datasets (>1 million cells). The tool requires the target table to pre-exist and supports various database types including ClickHouse, MySQL, Oracle, PostgreSQL, and SQL Server. Its strength lies in intelligent work distribution, whether using file-based distribution like our DataDriven approach, or other methods like CTID (PostgreSQL-specific), RangeId (numeric ranges), or Random (modulo-based distribution).
Performance Analysis: Where Theory Meets Reality
We tested four different table configurations to understand how PostgreSQL constraints and logging independently affect loading performance. Each test was run multiple times, reporting the best result to minimize noise from network variability or system background tasks.
Configuration 1: WITH PK / LOGGED
Standard production table with primary key on o_orderkey and full WAL durability:
| Degree of Parallelism | Load Time (seconds) | Speedup |
|---|---|---|
| 1 | 50.5 | 1.0x |
| 2 | 28.8 | 1.8x |
| 4 | 17.8 | 2.8x |
| 8 | 16.1 | 3.1x |
| 16 | 19.2 | 2.6x |
Peaks at 8 workers (3.1x speedup). Constraint checking and WAL logging create severe contention.
Configuration 2: WITH PK / UNLOGGED
Primary key with WAL logging disabled:
| Degree of Parallelism | Load Time (seconds) | Speedup |
|---|---|---|
| 1 | 46.3 | 1.0x |
| 2 | 25.5 | 1.8x |
| 4 | 14.5 | 3.2x |
| 8 | 9.3 | 5.0x |
| 16 | 7.8 | 5.9x |
Removing WAL overhead significantly improves scaling. Continues to 16 workers due to reduced contention.
Configuration 3: WITHOUT PK / LOGGED
No constraints, WAL logging enabled:
| Degree of Parallelism | Load Time (seconds) | Speedup |
|---|---|---|
| 1 | 45.3 | 1.0x |
| 2 | 24.2 | 1.9x |
| 4 | 13.2 | 3.4x |
| 8 | 8.7 | 5.2x |
| 16 | 8.7 | 5.2x |
Better than WITH PK/LOGGED but plateaus at 8 workers due to WAL contention.
Configuration 4: WITHOUT PK / UNLOGGED
Maximum performance configuration - no constraints, no WAL:
| Degree of Parallelism | Load Time (seconds) | Speedup |
|---|---|---|
| 1 | 44.5 | 1.0x |
| 2 | 25.4 | 1.8x |
| 4 | 13.4 | 3.3x |
| 8 | 7.8 | 5.7x |
| 16 | 5.1 | 8.7x |
Best scaling - achieves 8.7x speedup at 16 workers, finally hitting network bandwidth limits.
Visual Performance Comparison
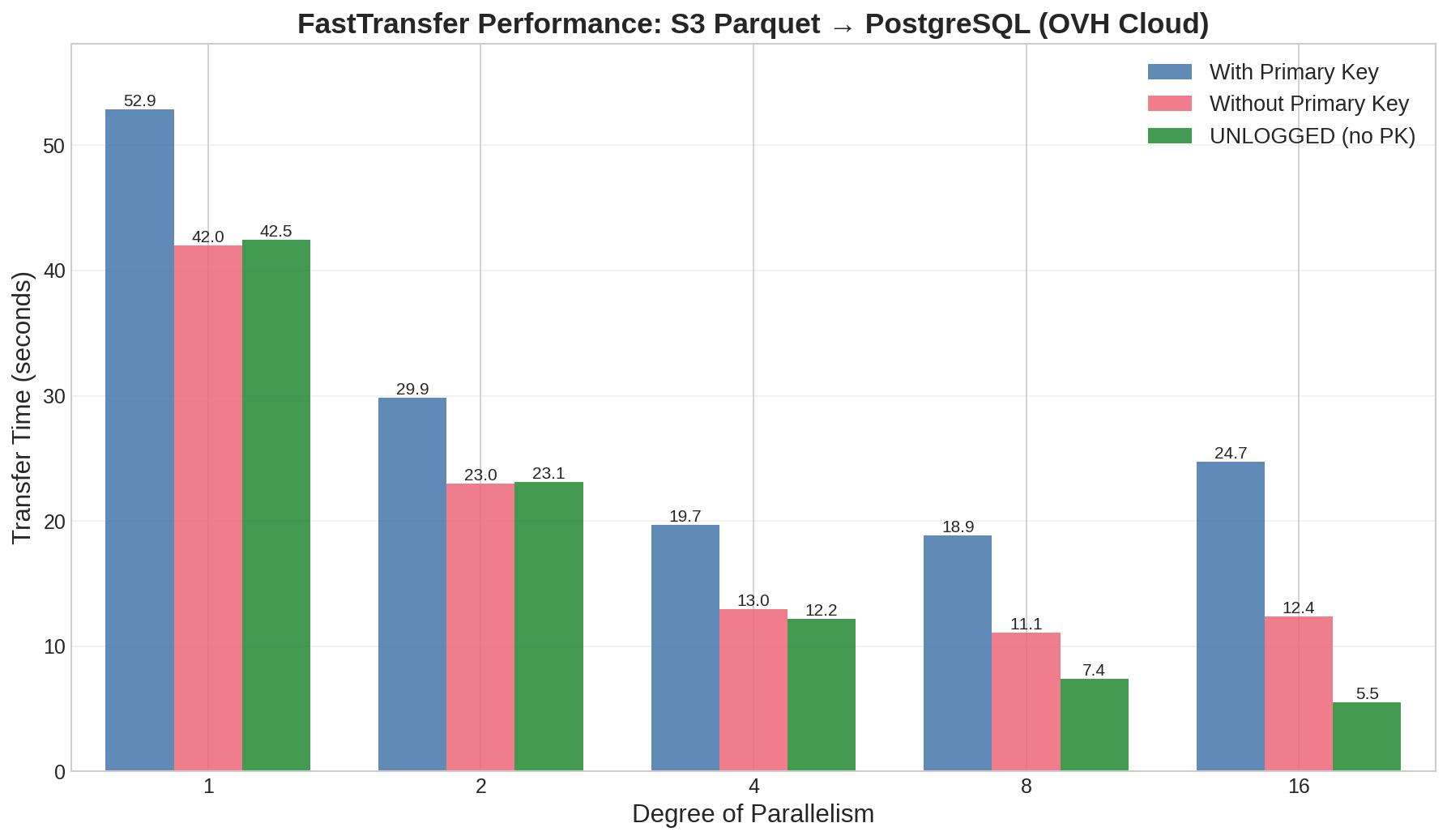
The comparison reveals how primary keys and WAL logging independently bottleneck performance. WITHOUT PK/UNLOGGED achieves the best scaling (8.7x at 16 workers), while WITH PK/LOGGED caps at 3.1x. The intermediate configurations show each factor’s impact: removing the primary key or disabling WAL each provide significant improvements, with their combination delivering maximum performance.
Network and I/O Considerations
Different configurations reveal different bottlenecks:
- WITH PK / LOGGED: Constraint checking + WAL overhead limits to 3.1x
- WITH PK / UNLOGGED: WAL removal allows 5.9x scaling
- WITHOUT PK / LOGGED: WAL contention plateaus at 5.2x
- WITHOUT PK / UNLOGGED: Best scaling at 8.7x (467.8 MiB in 5.1s ≈ 92 MB/s)
At 92 MB/s with 4 Gbps network (~500 MB/s) and 1465 MiB/s local NVMe capacity, neither network nor disk I/O are the bottleneck. The limitation could come from several sources: S3 object storage throughput, DuckDB Parquet parsing overhead, or PostgreSQL’s internal coordination when multiple workers write concurrently to the same table.
Conclusion
FastTransfer achieves 5.1-second load times for 467.8 MiB of Parquet data from OVH S3 to PostgreSQL, reaching 92 MB/s throughput with WITHOUT PK/UNLOGGED configuration at degree 16. Testing four configurations reveals that primary keys and WAL logging each independently constrain performance, with optimal settings varying from degree 8 (LOGGED) to degree 16+ (UNLOGGED). The results demonstrate that cloud-based data pipelines can achieve strong performance when configuration matches use case requirements.
About FastTransfer
FastTransfer is a commercial high-performance data migration tool developed by arpe.io. It provides parallel data transfer capabilities across multiple database platforms including PostgreSQL, MySQL, Oracle, SQL Server, ClickHouse, and DuckDB.
Key Features:
- Advanced parallelization strategies for optimal performance
- Cross-platform compatibility with major databases
- Flexible configuration for various data migration scenarios
- Production-ready with comprehensive logging and monitoring
For licensing information, support options, and to request a trial, visit the official documentation.