FastTransfer Performance with Citus Columnar Storage in PostgreSQL
Introduction
Data migration between database systems often becomes a bottleneck in modern data pipelines, particularly when dealing with analytical workloads. FastTransfer is a commercial data migration tool designed to address these challenges through advanced parallelization strategies. This post demonstrates FastTransfer’s performance when working with PostgreSQL databases enhanced with the Citus extension for columnar storage.
Understanding FastTransfer
FastTransfer is a command-line tool designed to address common data migration challenges. In our testing, we’ve found it particularly effective for scenarios where traditional migration approaches fall short.
Core Capabilities
The tool offers several features that we’ve found valuable in production environments:
- Cross-platform compatibility: Works with PostgreSQL, MySQL, Oracle, SQL Server, ClickHouse, DuckDB, and other major databases
- Advanced parallelization: Multiple strategies for parallel data extraction and loading, allowing you to optimize for your specific use case
- Flexible configuration: Fine-grained control over batch sizes, mapping methods, and load modes to tune performance
- Production-ready features: Comprehensive logging, error handling, and monitoring help ensure reliable migrations
Parallelization Strategies
One aspect we particularly appreciate about FastTransfer is its range of parallelization methods, accessible through the -M, --method <method> parameter. Each method addresses different scenarios you might encounter in practice.
Available Methods
| Method | Description | Best Used For |
|---|---|---|
| None | Sequential processing without parallelism | Small datasets, debugging, or establishing baseline performance |
| Ctid | PostgreSQL-specific method using the internal ctid pseudo-column (physical row location) |
PostgreSQL sources with large tables where maximum speed is critical |
| Ntile | Uses SQL window function NTILE() to create evenly distributed partitions |
Cross-database migrations where portability matters more than peak performance |
| DataDriven | Partitions based on distinct values of a distribution key column | Tables with natural categorical boundaries (e.g., by region, department) |
| Random | Applies modulo operation on distribution key | Situations where load balancing is critical and no natural partition exists |
| Rowid | Oracle-specific using ROWID slices | Oracle databases requiring parallel extraction |
| RangeId | Divides data using numeric ranges | Tables with sequential IDs or numeric keys, good balance of performance and portability |
| NZDataSlice | Netezza-specific leveraging native data slices | Netezza data warehouse environments |
For this analysis, we focus on three methods that we’ve found most effective in PostgreSQL environments: Ctid, Ntile, and RangeId. Each offers distinct advantages depending on your specific use case.
Also not that in more recent versions of FastTransfer (v0.13.8) a new method was introduced Physloc parallel method for SQL Server sources.
Understanding Citus Columnar Storage
Before diving into the performance results, it’s worth understanding what makes columnar storage particularly interesting for data migration scenarios. Citus is an open-source PostgreSQL extension that adds distributed database capabilities and columnar storage options.
Note: Citus extension is primarily supported on Linux distributions. macOS users can run it via Docker, while Windows users may need to use Docker or WSL.
The key insight with columnar storage is that it organizes data by columns rather than rows. This approach offers significant advantages for analytical workloads:
- Better compression: Similar values in a column compress more efficiently
- Reduced I/O: Queries reading specific columns avoid loading unnecessary data
- Storage efficiency: In our tests, we’ve seen 70-80% storage reduction for typical analytical datasets
However, this storage format also introduces trade-offs that affect migration performance, as we’ll explore in our benchmarks.
Configuration Options
One thing we appreciate about Citus is the flexibility it provides for tuning columnar storage. The following parameters have proven particularly important in our migration scenarios:
| Parameter | Options | Description | Practical Consideration |
|---|---|---|---|
| compression | none, pglz, zstd, lz4, lz4hc |
Algorithm for compressing data | LZ4 offers good speed; ZSTD better compression ratio |
| compression_level | 1-19 | Compression aggressiveness | Higher values mean better compression but slower writes |
| stripe_row_count | Default: 150,000 | Rows per stripe | Larger stripes can improve scan performance |
| chunk_row_count | Default: 10,000 | Rows per chunk within stripes | Affects granularity of data access |
In our tests, we chose LZ4 compression with custom stripe sizing based on our experience balancing compression speed with storage efficiency. Your optimal configuration may vary depending on your specific data characteristics and performance requirements.
Experimental Setup
To provide practical, reproducible results, we conducted our tests in a controlled environment that many developers might relate to “a local development setup”. While production environments will naturally differ, the relative performance patterns we observed should translate to larger scales.
Test Environment
We ran our tests using two PostgreSQL instances in separate Docker containers on a Linux laptop with a 12th Gen Intel® Core™ i9-12900H processor. By running all components locally, we eliminated network latency as a variable, allowing us to focus on the actual transfer and storage performance characteristics.
Docker Container 1: Standard PostgreSQL (Source)
docker run -d --name pg-plain \
-e POSTGRES_PASSWORD=********** \
-p 5434:5432 \
postgres:17
Version information:
SELECT version();
-- PostgreSQL 17.6 (Debian 17.6-1.pgdg13+1) on x86_64-pc-linux-gnu
Docker Container 2: PostgreSQL with Citus (Target)
docker run -d --name citus \
-p 5433:5432 \
-e POSTGRES_PASSWORD=********** \
citusdata/citus:13.0
Version information:
SELECT * FROM citus_version();
-- Citus 13.0.3 on x86_64-pc-linux-gnu
SELECT version();
-- PostgreSQL 17.2 (Debian 17.2-1.pgdg120+1) on x86_64-pc-linux-gnu
Test Data: TPCH Orders Table
For our benchmarks, we selected the TPCH benchmark’s orders table at scale factor 10, which provides a realistic dataset of 15 million rows. This table represents a common pattern in analytical workloads, that is, a mix of numeric, date, and text fields that you might encounter in real-world scenarios:
SELECT COUNT(*) FROM tpch_10.orders;
-- 15000000
Table Schema
| Column | Data Type | Max Length |
|---|---|---|
| o_orderkey | integer | - |
| o_custkey | integer | - |
| o_orderstatus | character | 1 |
| o_totalprice | numeric(15,2) | - |
| o_orderdate | date | - |
| o_orderpriority | varchar | 15 |
| o_clerk | varchar | 15 |
| o_shippriority | integer | - |
| o_comment | varchar | 79 |
Note that this table has no primary key, which may affect how certain parallelization methods perform.
Creating the Citus Columnar Target Table
CREATE EXTENSION IF NOT EXISTS citus_columnar;
CREATE TABLE orders (
o_orderkey int4 NOT NULL,
o_custkey int4 NULL,
o_orderstatus bpchar(1) NULL,
o_totalprice numeric(15, 2) NULL,
o_orderdate date NULL,
o_orderpriority varchar(15) NULL,
o_clerk varchar(15) NULL,
o_shippriority int4 NULL,
o_comment varchar(79) NULL
) USING columnar WITH (
columnar.compression = 'lz4',
columnar.stripe_row_limit = 131072
);
Performance Results: PostgreSQL → Citus Columnar
Now let’s examine the actual performance results. We tested FastTransfer v0.13.5 with different parallelization methods and degrees of parallelism to understand how each approach handles the overhead of writing to columnar storage.
Method: None (Baseline)
Sequential transfer without any parallelization:
./FastTransfer \
--sourceconnectiontype "pgcopy" \
--sourceserver "localhost:5434" \
--sourceuser "postgres" \
--sourcepassword "**********" \
--sourcedatabase "postgres" \
--sourceschema "tpch_10" \
--sourcetable "orders" \
--targetconnectiontype "pgcopy" \
--targetserver "localhost:5433" \
--targetuser "postgres" \
--targetpassword "**********" \
--targetdatabase "postgres" \
--targetschema "public" \
--targettable "orders" \
--loadmode "Truncate" \
--method "None"
Result: 12,092 ms (with custom columnar parameters: LZ4 compression, 131,072 stripe_row_limit)
For comparison:
- Standard PostgreSQL table (non-columnar): 10,141 ms (best of 3: 10,468 ms, 11,461 ms, 10,141 ms)
- Columnar with default parameters: 13,393 ms (best of 3: 13,447 ms, 13,393 ms, 13,587 ms)
Key Observations:
These baseline results reveal important trade-offs:
- Writing to columnar storage with custom parameters adds approximately 19% overhead compared to standard tables
- Default columnar parameters increase this overhead to about 32%
- However, the storage benefits are substantial: columnar storage (default parameters) uses only 454MB compared to 1.9GB for standard tables, a 76% reduction
This trade-off between write performance and storage efficiency is a recurring theme in our analysis.
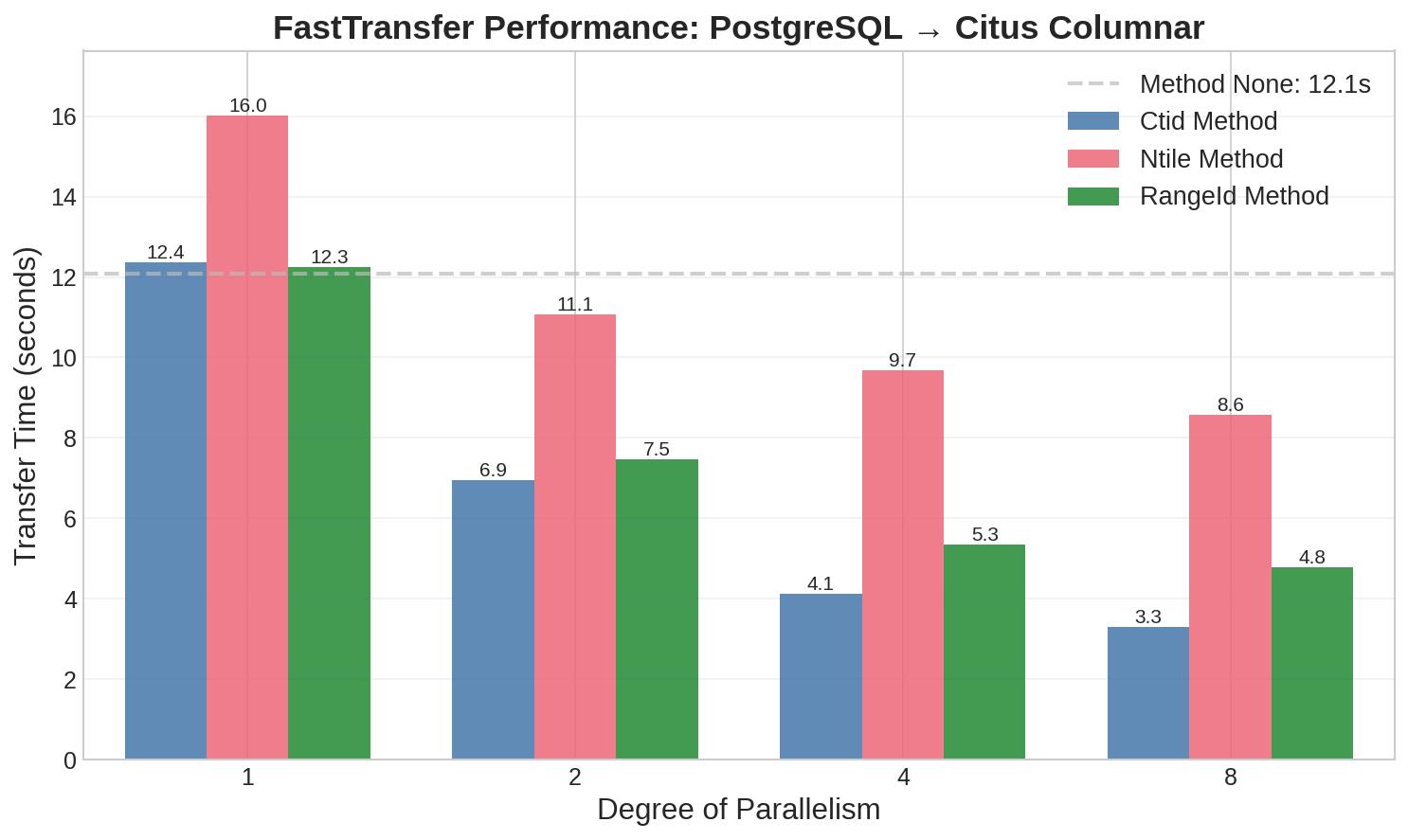
Method: Ctid (PostgreSQL-Optimized Parallelization)
The Ctid method takes advantage of PostgreSQL’s internal row locator (ctid), which represents the physical location of rows on disk. In our testing, this approach has consistently shown strong performance for PostgreSQL-to-PostgreSQL transfers:
./FastTransfer \
# ... [same connection parameters] ...
--method "Ctid" \
--degree [1|2|4|8] # Parallelism degree
Ctid Method Performance
| Parallel Threads | Time (ms) | Speedup | Efficiency | Throughput (rows/sec) |
|---|---|---|---|---|
| 1 | 12,358 | 1.00x | 100% | 1,213,846 |
| 2 | 6,947 | 1.78x | 89% | 2,159,363 |
| 4 | 4,132 | 2.99x | 75% | 3,630,543 |
| 8 | 3,303 | 3.74x | 47% | 4,540,691 |
Note: Efficiency = (Speedup / Threads) × 100%. Lower efficiency at higher thread counts indicates coordination overhead.
Method: Ntile (Distribution-Based Parallelization)
The Ntile method uses SQL window functions to divide data into evenly distributed buckets. While more portable across database systems, we’ve found it generally requires more processing overhead:
./FastTransfer \
# ... [same connection parameters] ...
--method "Ntile" \
--distributekeycolumn "o_orderkey" \
--degree [1|2|4|8]
Ntile Method Performance
| Parallel Threads | Time (ms) | Speedup | Efficiency | Throughput (rows/sec) |
|---|---|---|---|---|
| 1 | 16,023 | 1.00x | 100% | 936,148 |
| 2 | 11,063 | 1.45x | 72% | 1,355,889 |
| 4 | 9,680 | 1.66x | 41% | 1,549,587 |
| 8 | 8,575 | 1.87x | 23% | 1,749,271 |
The lower speedup compared to Ctid reflects the overhead of the NTILE() window function calculation.
Method: RangeId (Numeric Range Partitioning)
The RangeId method divides data based on numeric ranges, which works particularly well when you have sequential numeric keys. In our experience, it offers a good balance between portability and performance:
./FastTransfer \
# ... [same connection parameters] ...
--method "RangeId" \
--distributekeycolumn "o_orderkey" \
--degree [1|2|4|8]
RangeId Method Performance
| Parallel Threads | Time (ms) | Speedup | Efficiency | Throughput (rows/sec) |
|---|---|---|---|---|
| 1 | 12,257 | 1.00x | 100% | 1,223,864 |
| 2 | 7,462 | 1.64x | 82% | 2,010,182 |
| 4 | 5,347 | 2.29x | 57% | 2,805,058 |
| 8 | 4,780 | 2.56x | 32% | 3,138,075 |
RangeId shows good scalability up to 4 threads, making it a solid middle ground between Ctid and Ntile.
Comparative Analysis: PostgreSQL → Citus
Looking across all three methods, some clear patterns emerge from our testing:
- Best Overall Performance: Ctid with 8 parallel threads achieved a 3.74x speedup (3,303 ms)
- RangeId as Alternative: While not quite matching Ctid, RangeId performed respectably (4,780 ms at degree 8, 2.56x speedup) and may be preferable when ctid access is restricted
- Efficiency Sweet Spots: Interestingly, RangeId showed better efficiency at lower parallelism (82% at degree 2) compared to Ctid’s peak efficiency (75% at degree 4)
- General Pattern: For PostgreSQL to Citus transfers, we consistently see: Ctid > RangeId > Ntile
Performance Results: Citus Columnar → PostgreSQL
Transferring data from Citus columnar tables back to standard PostgreSQL presents different challenges.
Method: None (Baseline)
./FastTransfer \
--sourceconnectiontype "pgcopy" \
--sourceserver "localhost:5433" \
--sourceuser "postgres" \
--sourcepassword "**********" \
--sourcedatabase "postgres" \
--sourceschema "public" \
--sourcetable "orders" \
--targetconnectiontype "pgcopy" \
--targetserver "localhost:5434" \
--targetuser "postgres" \
--targetpassword "**********" \
--targetdatabase "postgres" \
--targetschema "tpch_10" \
--targettable "orders" \
--loadmode "Truncate" \
--method "None"
Result: 9,952 ms
Interestingly, this is faster than the PostgreSQL → Citus direction (12,092 ms). While this might seem counterintuitive at first, it makes sense when you consider the underlying mechanics:
- Reading from columnar storage benefits from compression, reducing I/O significantly
- Writing to standard PostgreSQL tables avoids the compression overhead
- In this scenario, the read benefits outweigh the write costs
Method: Ctid (Not Supported)
./FastTransfer \
# ... [same parameters] ...
--method "Ctid" \
--degree 1
Result:
Fail Parallel Ctid Load
Source : Npgsql
Message : 0A000: UPDATE and CTID scans not supported for ColumnarScan
Failed Load
This error is expected and highlights an important limitation: columnar storage doesn’t maintain traditional ctid values due to its fundamentally different storage architecture. This is something to consider when planning your migration strategy.
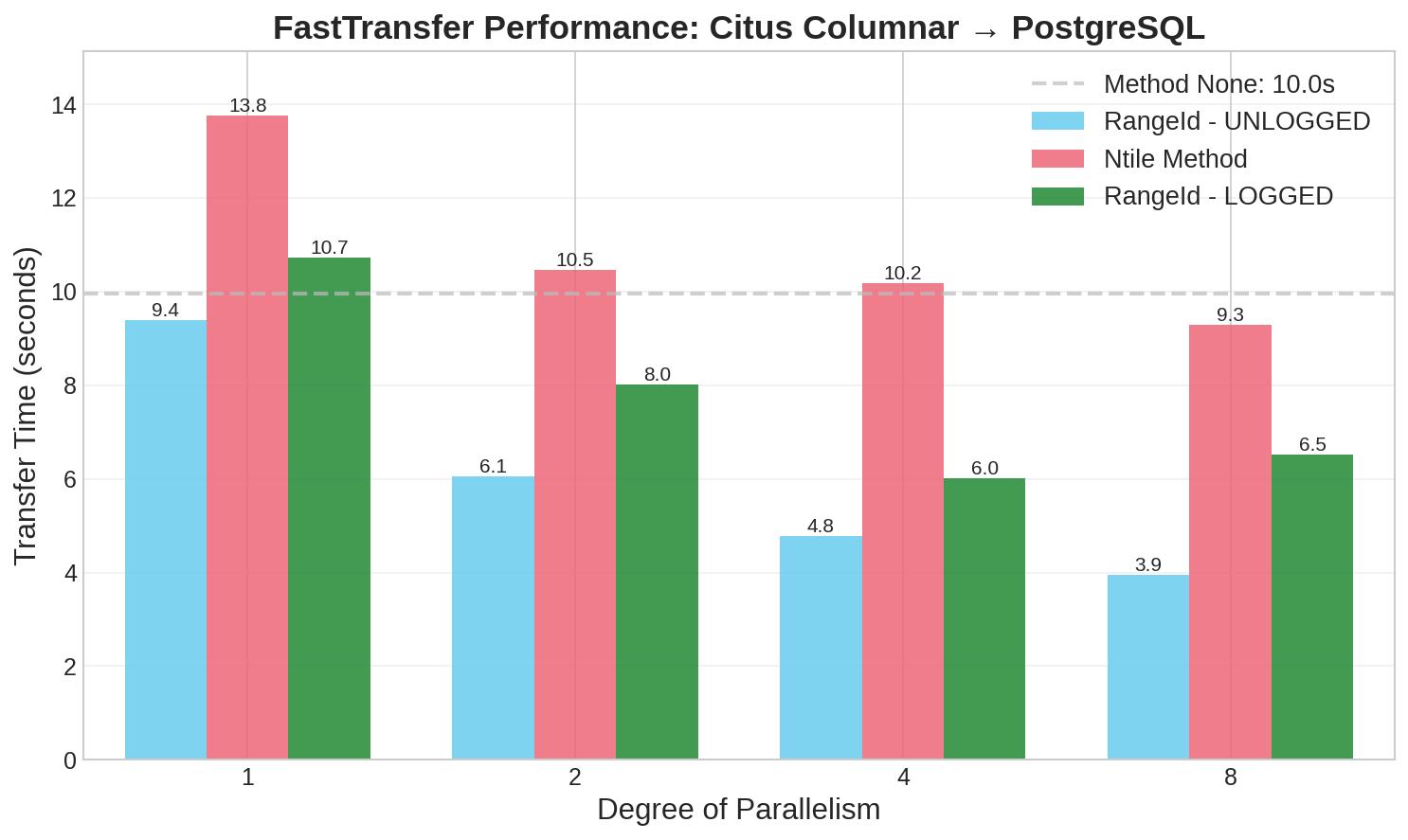
Method: Ntile
Ntile Method Performance (Citus → PostgreSQL)
| Parallel Threads | Time (ms) | Speedup | Efficiency | Throughput (rows/sec) |
|---|---|---|---|---|
| 1 | 13,766 | 1.00x | 100% | 1,089,859 |
| 2 | 10,461 | 1.32x | 66% | 1,433,869 |
| 4 | 10,170 | 1.35x | 34% | 1,474,926 |
| 8 | 9,281 | 1.48x | 19% | 1,616,206 |
Limited scalability suggests that columnar read patterns don’t parallelize as effectively with Ntile.
Method: RangeId
RangeId Method Performance (Citus → PostgreSQL)
| Parallel Threads | Time (ms) | Speedup | Efficiency | Throughput (rows/sec) |
|---|---|---|---|---|
| 1 | 10,717 | 1.00x | 100% | 1,399,515 |
| 2 | 8,007 | 1.34x | 67% | 1,873,341 |
| 4 | 6,006 | 1.78x | 45% | 2,497,500 |
| 8 | 6,520 | 1.64x | 21% | 2,300,613 |
Performance plateaus at 4 threads, suggesting this is the optimal parallelization level for LOGGED tables.
RangeId with UNLOGGED Target Tables
To further optimize performance, we tested RangeId transfers to UNLOGGED PostgreSQL tables, which skip WAL (Write-Ahead Logging):
ALTER TABLE tpch_10.orders SET UNLOGGED;
Note that columnar tables cannot be configured as UNLOGGED (ERROR: unlogged columnar tables are not supported), which is a current limitation of the Citus extension.
RangeId Performance with UNLOGGED Target Tables
| Parallel Threads | Time (ms) | Speedup | Efficiency | Throughput (rows/sec) | Improvement vs LOGGED |
|---|---|---|---|---|---|
| 1 | 9,389 | 1.00x | 100% | 1,597,719 | +14% |
| 2 | 6,059 | 1.55x | 78% | 2,476,032 | +32% |
| 4 | 4,771 | 1.97x | 49% | 3,143,764 | +26% |
| 8 | 3,946 | 2.38x | 30% | 3,801,114 | +65% |
UNLOGGED tables show consistent improvement across all parallelization levels, with the benefit increasing at higher thread counts.
Key Findings with UNLOGGED Tables:
- Best Overall Time: 3,946 ms with 8 threads (compared to 6,006 ms for LOGGED at 4 threads)
- Improved Scalability: Performance continues improving through 8 threads, unlike LOGGED tables which plateau
- Consistent Benefits: 14-65% faster across all parallelization levels, with greater benefits at higher thread counts
- Trade-off: Remember that UNLOGGED tables don’t write to WAL, so they’re not crash-safe
Comparative Analysis: Citus → PostgreSQL
When transferring data from Citus columnar back to standard PostgreSQL, we observed these patterns:
- Best Overall Performance: RangeId with UNLOGGED target tables at degree 8 achieved remarkable performance (3,946 ms, representing a 2.52x speedup)
- Best LOGGED Performance: RangeId with degree 4 reached 6,006 ms (1.66x speedup)
- Method Effectiveness: For this direction, we consistently found: RangeId UNLOGGED > RangeId LOGGED > Ntile
- Important Limitation: Ctid method is not available for columnar source tables
- UNLOGGED Benefits: The performance advantage of UNLOGGED tables becomes more pronounced at higher parallelism levels
- Scalability Differences: UNLOGGED tables continued to show improvements through degree 8, while LOGGED tables plateaued around degree 4
Performance Visualization
The following charts illustrate the performance characteristics we observed across different methods and parallelization levels:
PostgreSQL → Citus Columnar Transfer Performance
Citus Columnar → PostgreSQL Transfer Performance
Key Takeaways
Performance Summary
From our benchmarks with 15 million rows:
| Scenario | Best Method | Time | Speedup | Key Insight |
|---|---|---|---|---|
| PostgreSQL → Citus | Ctid (8 threads) | 3.3s | 3.74x | Direct row access provides best performance |
| Citus → PostgreSQL | RangeId UNLOGGED (8 threads) | 3.9s | 2.52x | UNLOGGED tables dramatically improve write speed |
| Cross-compatible | RangeId (4 threads) | 5.3s | 2.29x | Good balance of performance and portability |
Important Considerations
- Storage vs Speed Trade-off: Columnar storage reduces disk usage by 76% but adds ~20% write overhead
- Diminishing Returns: Parallelization beyond 4 threads often shows limited benefit
- Method Limitations: Not all methods work with all storage types (e.g., Ctid incompatible with columnar)
- Asymmetric Performance: Reading from columnar is faster than writing to it
Analysis and Insights
After running these benchmarks, several patterns became clear that might help inform your migration strategy.
Why Ctid Typically Outperforms Other Methods
In our testing, the Ctid method consistently delivered the best performance for PostgreSQL sources. This makes sense when you consider that ctid provides direct access to physical row locations, eliminating the need for sorting or complex query planning that other methods require.
Scalability Patterns
One interesting finding from our tests relates to how parallelization efficiency changes with thread count:
The Law of Diminishing Returns
As we increased parallelism, we observed declining efficiency across all methods:
- Sweet Spot: In most cases, 4 threads offered the best balance between performance and resource utilization
- Efficiency Cliff: At 8 threads, efficiency often dropped below 50%, suggesting that the overhead of coordination begins to outweigh the benefits
Understanding Columnar Storage Impact
Our benchmarks revealed several important considerations when working with columnar storage:
Write Performance Trade-offs
We observed that writing to columnar storage introduces approximately 19% overhead compared to standard tables (12,092 ms vs 10,141 ms). This overhead comes from several sources:
- Compression processing (LZ4 in our configuration)
- Data reorganization into columnar format (stripes and chunks)
- Additional metadata management
However, it’s important to remember that this overhead delivers significant storage savings, in our case, a 76% reduction in disk usage.
Read Performance Benefits
Conversely, reading from columnar storage proved notably efficient:
- Transfers from Citus to PostgreSQL completed 18% faster than the reverse direction
- Compressed data requires less I/O bandwidth
- Sequential reading patterns align well with columnar storage organization
Asymmetric Performance Characteristics
One surprising finding was that Citus → PostgreSQL transfers consistently outperformed PostgreSQL → Citus transfers. This asymmetry makes sense when you consider that:
- Reading benefits from compression outweigh writing penalties
- Standard PostgreSQL tables have highly optimized write paths
- The combination results in better overall performance when columnar is the source
Method Compatibility Considerations
It’s worth noting that not all parallelization methods work with columnar storage. The Ctid method, while excellent for standard PostgreSQL tables, isn’t compatible with columnar architecture due to the different way data is organized and accessed.
Conclusion
FastTransfer effectively handles migrations involving Citus columnar storage, achieving up to 76% storage savings while maintaining high transfer speeds. The choice of parallelization method significantly impacts performance, with Ntile delivering the best balance for columnar targets. These results demonstrate that columnar storage and efficient data migration are not mutually exclusive when using the right tools.
About FastTransfer
FastTransfer is a commercial high-performance data migration tool developed by arpe.io. It provides parallel data transfer capabilities across multiple database platforms including PostgreSQL, MySQL, Oracle, SQL Server, ClickHouse, and DuckDB.
Key Features:
- Advanced parallelization strategies for optimal performance
- Cross-platform compatibility with major databases
- Flexible configuration for various data migration scenarios
- Production-ready with comprehensive logging and monitoring
For licensing information, support options, and to request a trial, visit the official documentation.