Running a private Qwen3.6 Coding Agent on Scaleway
This is the Scaleway sequel to two previous posts on self-hosted coding agents: the AWS run where we deployed a 27B model on a g5.xlarge, and the consumer-GPU experiment where we squeezed a smaller model into 8 GB of laptop VRAM. The procedure is the same; the hardware and the model are bigger. We deploy Qwen3.6-35B-A3B on a single NVIDIA L40S GPU, serve it with llama.cpp, wire it to OpenCode, and run ToolCall-15 to measure tool-calling quality. Qwen3.6-35B-A3B is a Mixture-of-Experts model with 35B total parameters but only 3B active per token, so decode is fast despite the model size. The quantization is Unsloth’s UD-Q6_K_XL at ~30 GB, which fits in the L40S’s 48 GB of VRAM with enough headroom for a 64K-token KV cache. Everything runs on a single L40S-1-48G instance in fr-par-2.
Outline
- Prerequisites
- Security Group
- Find the Right Image
- Launch the GPU Instance
- Connect via SSH
- Verify the GPU
- Build llama.cpp with CUDA
- Download the Model
- Start llama-server
- Validate with ToolCall-15
- Connect OpenCode to the Remote Server
- Using OpenCode with Qwen3.6-35B-A3B
- Stop, Restart, Snapshot, Teardown
- Cost
- Reflections
1. Prerequisites
On the local machine (Linux Mint, Ubuntu-based), we need:
curl,ssh, andjq(used to parsescw -o jsonoutput)- An SSH key dedicated to this workload at
~/.ssh/scaleway_l40s(private) and~/.ssh/scaleway_l40s.pub(public)
The Scaleway CLI is installed in step 1 below; OpenCode is installed in section 11. Everything else (llama.cpp, the model, Node.js) runs on the remote instance.
0. Complete Scaleway identity verification at https://console.scaleway.com/account/identity first. Without it, the GPU launch in section 4 fails with a quota error.
1. Install the Scaleway CLI from the official GitHub binary.
sudo curl -L https://github.com/scaleway/scaleway-cli/releases/download/v2.55.0/scaleway-cli_2.55.0_linux_amd64 \
-o /usr/local/bin/scw
sudo chmod +x /usr/local/bin/scw
scw version
Version 2.55.0
BuildDate 2026-04-20T09:25:04Z
GoVersion go1.26.2
GitBranch HEAD
GitCommit 8ef8e6fc
GoArch amd64
GoOS linux
UserAgentPrefix scaleway-cli
2. Generate an API key at https://console.scaleway.com/iam/api-keys, then run scw init. A CLI profile is a local entry in ~/.config/scw/config.yaml; a Scaleway Project is a server-side billing/IAM scope. We use the default project for scw init only, then create a dedicated llm-exploration project in step 3.
Create the API key on the Scaleway web console
scw init

Scaleway CLI scw init splash
Answer n when asked to upload an existing ssh key; we register a dedicated key in step 5. Set zone fr-par-2, region fr-par.
scw config dump
access_key: SCWXXXXXXXXXXXXXXXXX
secret_key: ********-xxxx-xxxx-xxxx-xxxxxxxxxxxx
default_organization_id: aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa
default_project_id: aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa
default_region: fr-par
default_zone: fr-par-2
scw account project list
ID NAME ORGANIZATION ID CREATED AT DESCRIPTION
aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa S3 aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa 3 months ago ...
3. Create a dedicated project for clean teardown.
PROJECT_ID=$(scw account project create \
name=llm-exploration \
description="Self-hosted LLM coding agent exploration" \
-o json | jq -r .id)
echo $PROJECT_ID
# bbbbbbbb-bbbb-bbbb-bbbb-bbbbbbbbbbbb
scw account project list
ID NAME ORGANIZATION ID CREATED AT DESCRIPTION
aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa S3 aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa 3 months ago ...
bbbbbbbb-bbbb-bbbb-bbbb-bbbbbbbbbbbb llm-exploration aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa 31 seconds ago Self-hosted LLM coding agent exploration
The CLI’s default project (pointing at S3) is left untouched. To keep PROJECT_ID across shell sessions:
echo "export PROJECT_ID=bbbbbbbb-bbbb-bbbb-bbbb-bbbbbbbbbbbb" >> ~/.zshrc
4. Confirm the L40S server types are offered in fr-par-2:
scw instance server-type list zone=fr-par-2 | grep -i l40s
L40S-8-48G € 0.186656 Block, Scratch 64 8 768 GiB x64 20 GB available 16
L40S-4-48G € 0.093328 Block, Scratch 32 4 384 GiB x64 10 GB available 8
L40S-2-48G € 0.046664 Block, Scratch 16 2 192 GiB x64 5.0 GB available 4
L40S-1-48G € 0.023332 Block, Scratch 8 1 96 GiB x64 2.5 GB available 2
Columns, left to right: name, hourly_price, supported_storage, cpu, gpu, ram, arch, bandwidth, availability, max_file_systems. Two values are misleading as printed: hourly_price is actually per-minute (× 60 ≈ €1.40/hour, matching the pricing page), and bandwidth is in bits/sec, so “2.5 GB” reads as 2.5 Gbps.
An L40S-1-48G has one NVIDIA L40S GPU with 48 GB of GDDR6 VRAM (864 GB/s), 8 vCPUs (AMD EPYC 7413), 96 GB of system RAM, and 1.6 TB of local NVMe scratch. The L40S is Ada Lovelace generation (compute capability 8.9, sm_89), which matters for the llama.cpp build flags in section 7.
5. Register the SSH public key. Scaleway injects project-registered keys into ~root/.ssh/authorized_keys on every instance in that project.
scw iam ssh-key create \
name=scaleway-l40s \
public-key="$(cat ~/.ssh/scaleway_l40s.pub)" \
project-id=$PROJECT_ID
ID cccccccc-cccc-cccc-cccc-cccccccccccc
Name scaleway-l40s
PublicKey ssh-ed25519 AAAA...
Fingerprint 256 MD5:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx (ssh-ed25519)
CreatedAt now
UpdatedAt now
OrganizationID aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa
ProjectID bbbbbbbb-bbbb-bbbb-bbbb-bbbbbbbbbbbb
Disabled false
We also have a Host block in ~/.ssh/config:
Host scaleway-l40s
HostName PLACEHOLDER_PUBLIC_IP
User root
IdentityFile ~/.ssh/scaleway_l40s
IdentitiesOnly yes
ServerAliveInterval 60
ServerAliveCountMax 3
HostName is updated in section 4 once we have the public IP.
2. Security Group
Scaleway calls its stateful firewall an “Instance security group”. We create a dedicated one, so it can be deleted with the project at the end. Default security groups allow all inbound.
1. Get our current public IP address:
MY_IP=$(curl -4 -s ifconfig.me)
echo $MY_IP
# 203.0.113.42
2. Create the security group with default-deny inbound, default-allow outbound:
SG_ID=$(scw instance security-group create \
name=llm-exploration-sg \
description="Temporary SG for LLM exploration - SSH only" \
inbound-default-policy=drop \
outbound-default-policy=accept \
stateful=true \
project-id=$PROJECT_ID \
-o json | jq -r .security_group.id)
echo $SG_ID
# dddddddd-dddd-dddd-dddd-dddddddddddd
3. Allow SSH (port 22) inbound from our IP only:
scw instance security-group create-rule \
security-group-id=$SG_ID \
protocol=TCP \
direction=inbound \
action=accept \
ip-range=${MY_IP}/32 \
dest-port-from=22
ID eeeeeeee-eeee-eeee-eeee-eeeeeeeeeeee
Protocol TCP
Direction inbound
Action accept
IPRange 203.0.113.42/32
DestPortFrom 22
Position 1
Editable true
Zone fr-par-2
The /32 mask restricts access to our single IP. Editable: true distinguishes user-created rules from the default-policy implied rules. We do not open port 8080 (llama-server) on the security group; it is reached via SSH tunnel in section 11.
3. Find the Right Image
We list the GPU and ML images from Scaleway’s marketplace:
scw marketplace image list | grep -iE "gpu|ml" | head
a6c68db3-... ubuntu_jammy_gpu_os_12 Ubuntu Jammy GPU OS 12 [Machine Learning] Ubuntu 22.04 Jammy Jellyfish for Nvidia GPU and Machine Learning 6 days ago 3 years ago
61916874-... ubuntu_noble_gpu_os_12 Ubuntu Noble GPU OS 12 [Machine Learning] Ubuntu 24.04 Noble Numbat for Nvidia GPU and Machine Learning 6 days ago 1 year ago
741cfd27-... ubuntu_noble_gpu_os_13_nvidia Ubuntu Noble GPU OS 13 (Nvidia) [Machine Learning] Ubuntu 24.04 Noble Numbat for Nvidia GPU and Machine Learning 6 days ago 4 months ago
Three GPU-ready images. The “GPU OS 12” / “GPU OS 13” suffix indicates the NVIDIA driver generation: no CUDA toolkit is preinstalled. _gpu_os_12 ships driver 570.x (CUDA toolkits ≤ 12.8); _gpu_os_13_nvidia ships a 580-series driver (CUDA 13.x).
We pick ubuntu_jammy_gpu_os_12: longest fleet history, straightforward CUDA 12.6 path. _gpu_os_13_nvidia is avoided because the Unsloth Qwen3.6 docs warn: “Do NOT use CUDA 13.2 as you may get gibberish outputs. NVIDIA is working on a fix.” A 580-series driver makes 13.x the path of least resistance, so we stay on the 570 driver. Picking ubuntu_jammy_gpu_os_12 (22.04) over ubuntu_noble_gpu_os_12 (24.04) also avoids PEP 668: the global pip install in section 8 errors out on Noble’s externally-managed Python without a venv. The image bundles only the NVIDIA driver (570.x) and Container Toolkit (Docker); CUDA toolkit is installed in section 7. Default user is root.
4. Launch the GPU Instance
1. Launch the instance with a 100 GB persistent block volume (5K IOPS). That covers ~30 GB OS, ~30 GB model, ~8 GB CUDA toolkit, ~2 GB llama.cpp build, with ~30 GB headroom.
INSTANCE_ID=$(scw instance server create \
type=L40S-1-48G \
zone=fr-par-2 \
image=ubuntu_jammy_gpu_os_12 \
name=llm-exploration \
root-volume=block:100GB \
ip=new \
security-group-id=$SG_ID \
project-id=$PROJECT_ID \
tags.0=llm-exploration \
-o json | jq -r .id)
echo $INSTANCE_ID
# 33333333-eeee-ffff-aaaa-444444444444
root-volume=block:100GB is a persistent 5K IOPS Block volume (bills at €0.000118/GB/hour even when stopped). local: volumes are deprecated; the 1.6 TB NVMe scratch is ephemeral. ip=new allocates a routed IPv4 (“Zonal Flexible IP”) billed at €0.004/hour continuously, released only on instance deletion.
2. Wait for the instance to reach running:
scw instance server wait $INSTANCE_ID zone=fr-par-2
3. Retrieve the public IP (v2.55 uses public_ips array, not public_ip):
PUBLIC_IP=$(scw instance server get $INSTANCE_ID zone=fr-par-2 \
-o json | jq -r '.public_ips[0].address')
echo $PUBLIC_IP
# 198.51.100.10
4. Update the ~/.ssh/config HostName with PUBLIC_IP.
5. Connect via SSH
ssh scaleway-l40s
Accept the host-key fingerprint warning on first connection. All commands through section 12 run on the remote instance, as indicated by [REMOTE] in the section title.
6. [REMOTE] Verify the GPU
whoami
nvidia-smi
root
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 570.211.01 Driver Version: 570.211.01 CUDA Version: 12.8 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA L40S Off | 00000000:01:00.0 Off | 0 |
| N/A 30C P8 23W / 350W | 0MiB / 46068MiB | 0% Default |
+-----------------------------------------+------------------------+----------------------+
The L40S is idle at 23W with 46 GB usable VRAM (48 GB minus driver reserves). “CUDA Version: 12.8” is the maximum toolkit the driver will accept; no toolkit is installed yet.
We run everything below as root because the Scaleway GPU image ships with root as the only login user and the entire instance is destroyed at the end of the post. This is a deliberate trade-off for a throwaway exploration; for any longer-lived deployment, create an unprivileged user, run llama-server under it, and use sudo only where strictly needed.
7. [REMOTE] Build llama.cpp with CUDA
1. Install CUDA 12.6 from NVIDIA’s repo. Do not use Ubuntu’s nvidia-cuda-toolkit (CUDA 11.5, too old for sm_89). Remove it first if already installed:
apt-get remove --purge -y nvidia-cuda-toolkit 2>/dev/null || true
cd /tmp
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.1-1_all.deb
dpkg -i cuda-keyring_1.1-1_all.deb
The GPU OS 12 image ships /etc/apt/sources.list.d/cuda.list signed by cudatools.gpg. The cuda-keyring package adds a second source for the same URL signed by a different keyring, causing apt-get update to fail with a Conflicting values set for option Signed-By error. Remove the preinstalled source first:
rm -v /etc/apt/sources.list.d/cuda.list
apt-get update
apt-get install -y cuda-toolkit-12-6
Add CUDA to ~/.bashrc persistently:
echo 'export PATH=/usr/local/cuda-12.6/bin:$PATH' >> ~/.bashrc
echo 'export LD_LIBRARY_PATH=/usr/local/cuda-12.6/lib64:$LD_LIBRARY_PATH' >> ~/.bashrc
source ~/.bashrc
nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2024 NVIDIA Corporation
Built on Tue_Oct_29_23:50:19_PDT_2024
Cuda compilation tools, release 12.6, V12.6.85
Build cuda_12.6.r12.6/compiler.35059454_0
12.6 is above the 11.8 minimum for sm_89 and below the 13.2 that the Unsloth docs flag as producing gibberish on Qwen3.6. 12.4 or 12.8 are also acceptable.
2. Install build dependencies:
apt-get install -y \
pciutils build-essential cmake curl libcurl4-openssl-dev tmux
3. Clone llama.cpp. master post-2026-04-19 is needed for PR #19493 (Qwen3.5/3.6 MoE chat-template support):
git clone https://github.com/ggml-org/llama.cpp
cd llama.cpp
git log -1 --format='%h %ci %s'
# 1f3a8b2c 2026-04-22 14:02:11 +0000 server: emit reasoning_content for thinking-mode models
4. Configure and build with CUDA support, targeting the L40S’s compute capability:
cmake -B build \
-DBUILD_SHARED_LIBS=OFF \
-DGGML_CUDA=ON \
-DCMAKE_CUDA_ARCHITECTURES=89
cmake --build build --config Release -j8 \
--clean-first \
--target llama-server llama-cli llama-gguf-split
-DGGML_CUDA=ON enables GPU acceleration. -DCMAKE_CUDA_ARCHITECTURES=89 targets the L40S (Ada Lovelace, 8.9); targeting only one arch reduces build time from ~60 to ~7 minutes. Could NOT find OpenSSL and Could NOT find NCCL are harmless warnings (traffic is SSH-tunnelled; NCCL is multi-GPU only). -DLLAMA_CURL=ON is deprecated; libcurl is auto-detected. --clean-first is useful here for a guaranteed-fresh first build, but drop it on subsequent rebuilds: it wipes prior artefacts, defeats ccache, and forces the full ~7 minutes every time.
5. Copy the binaries to the home directory and confirm CUDA is wired in:
cp build/bin/llama-server build/bin/llama-cli build/bin/llama-gguf-split ~
~/llama-server --version
ggml_cuda_init: found 1 CUDA devices (Total VRAM: 45467 MiB):
Device 0: NVIDIA L40S, compute capability 8.9, VMM: yes, VRAM: 45467 MiB
version: 8940 (78433f606)
built with GNU 11.4.0 for Linux x86_64
The 45,467 MiB figure is slightly less than the 46,068 MiB nvidia-smi reported: driver and CUDA runtime overhead.
8. [REMOTE] Download the Model
1. Install huggingface_hub and hf_transfer (Rust parallel backend; the CLI binary is now hf):
pip install huggingface_hub hf_transfer
export HF_HUB_ENABLE_HF_TRANSFER=1
2. Download the single file we need from unsloth/Qwen3.6-35B-A3B-GGUF:
hf download unsloth/Qwen3.6-35B-A3B-GGUF \
--local-dir ~/models/Qwen3.6-35B-A3B-GGUF \
--include "*UD-Q6_K_XL*"
Fetching 1 files: 100%|██████| 1/1 [00:50<00:00, 50.62s/it]
Download complete: 100%|██████| 31.8G/31.8G [00:50<00:00, 629MB/s]
31.8 GB in 50 seconds, ≈629 MB/s (≈5.0 Gbps), saturating the instance’s egress link. For repeated reproductions, caching the GGUF in Scaleway Object Storage (s3-compatible, fr-par) and pulling via aws s3 cp over the internal network drops the transfer to ~5 seconds and survives full project deletion.
ls -lh ~/models/Qwen3.6-35B-A3B-GGUF/
df -h /
total 30G
-rw-r--r-- 1 root root 30G Apr 26 13:43 Qwen3.6-35B-A3B-UD-Q6_K_XL.gguf
Filesystem Size Used Avail Use% Mounted on
/dev/sda1 91G 51G 40G 57% /
51 GB used: model 30 GB, OS + packages ~14 GB, CUDA toolkit ~6 GB, llama.cpp build ~5 GB.
Qwen3.6-35B-A3B-UD-Q6_K_XL.gguf is Unsloth Dynamic 6-bit: attention and shared layers at 8-bit, expert FFNs at 6-bit. Per the model card: 35B total parameters, 3B active per token, 40 layers, 256 experts with 8 routed + 1 shared activated per token, 262K native context (extensible to ~1M with YaRN). With 48 GB VRAM, we step up from Q4 (sufficient for the 27B dense model) to Q6. The repository also has mmproj-F16.gguf for multimodal; skip it.
Sebastian Raschka has published an annotated architecture diagram in his LLM Architecture Gallery:
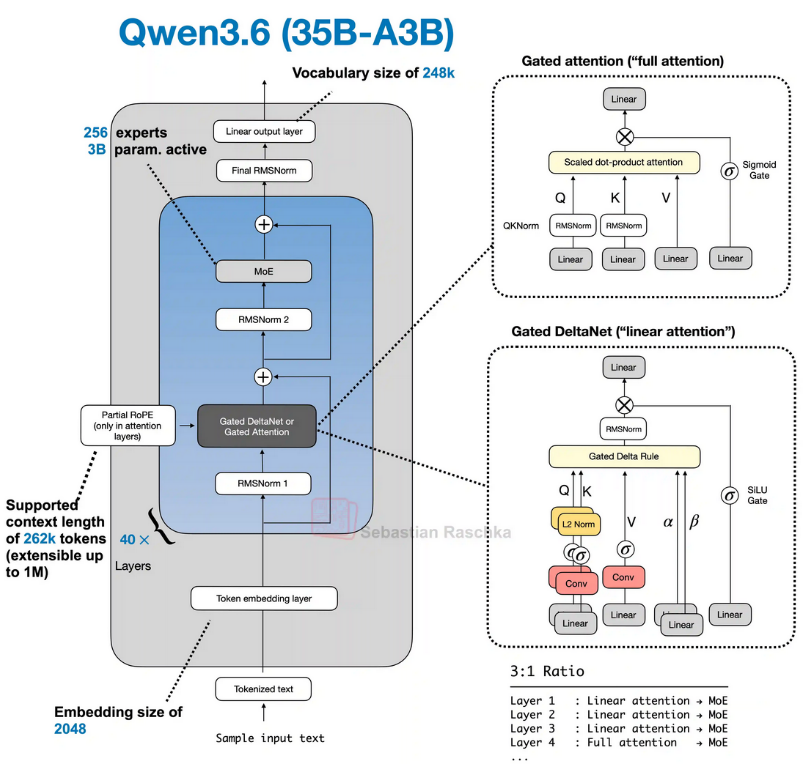
Qwen3.6-35B-A3B architecture, diagram by Sebastian Raschka, from his LLM Architecture Gallery. Reproduced with full credit; all rights to the original author.
Many thanks to Sebastian Raschka for maintaining the gallery.
Three terms from the diagram worth knowing:
- MoE (Mixture-of-Experts): instead of one big network that does everything, the model has 256 small specialist networks plus 1 generalist that always runs. For each word, a tiny “router” picks the 8 most relevant specialists. Big knowledge, small bill at runtime: 35B parameters in storage, ~3B actually used per word.
- Gated Attention: each attention head has a built-in volume knob. The model learns when a given head is useful and turns it down (or off) when it isn’t. Less noise, more stable training.
- Hybrid Attention: most of the 40 layers (30 of them) use a fast linear-attention variant called Gated DeltaNet, where the cost grows with the sequence length, not its square. The other 10 layers use the slower but more precise softmax (Gated) Attention. Mixing the two keeps long contexts affordable while keeping enough exact-attention layers to anchor precision.
9. [REMOTE] Start llama-server
Start llama-server in a tmux session so it persists if the SSH connection drops:
tmux new-session -d -s llmserver '
~/llama-server \
--model ~/models/Qwen3.6-35B-A3B-GGUF/Qwen3.6-35B-A3B-UD-Q6_K_XL.gguf \
--alias "unsloth/Qwen3.6-35B-A3B" \
--jinja \
-ngl 99 \
-fa on \
--ctx-size 65536 \
--cache-type-k q8_0 \
--cache-type-v q8_0 \
--temp 0.6 \
--top-p 0.95 \
--top-k 20 \
--min-p 0.0 \
--presence-penalty 0.0 \
--chat-template-kwargs "{\"enable_thinking\":true,\"preserve_thinking\":true}" \
--host 0.0.0.0 \
--port 8080 2>&1 | tee ~/llmserver.log
'
Flags explained:
--jinja: use the Jinja chat template from the GGUF metadata. Mandatory for tool calling. Without it, llama-server falls back to a generic ChatML template, and tool-call accuracy collapses.-ngl 99: offload all layers to GPU.-fa on: enable Flash Attention. Required when KV cache is quantized, and Ada Lovelace has hardware-accelerated FA kernels.--ctx-size 65536: 64K-token context. VRAM budget: model 30 GB + 64K q8_0 KV ~1 GB + DeltaNet recurrent state + activations + CUDA workspace ~0.8 GB ≈ 32 GB, leaving ~14 GB headroom. The KV cost is an order of magnitude below the dense-model textbook formula because only 10 of 40 layers run softmax attention (the other 30 are Gated DeltaNet with constant-size state) and those 10 layers use GQA with 2 KV heads against 16 Q heads.--cache-type-k q8_0 --cache-type-v q8_0: 8-bit KV cache. q4 produces malformed<tool_call>JSON frequently on thinking-mode models; Q8 is the conservative choice.--temp 0.6 --top-p 0.95 --top-k 20 --min-p 0.0: the Unsloth Qwen3.6 sampling recipe. Lower temperatures collapse thinking-mode chain-of-thought.--presence-penalty 0.0: trained default. Raise only if the model repeats phrases.--chat-template-kwargs '{"enable_thinking":true,"preserve_thinking":true}': carry thinking content across turns.preserve_thinkingis broken on the denseQwen3.6-27Bsibling (#22255) but works on the MoE.--host 0.0.0.0: bind on every interface. The security group from section 2 blocks external port 8080, so the practical exposure is limited to anything inside the instance. For defence in depth,--host 127.0.0.1matches the SSH-tunnel access pattern exactly and is the safer default for longer-lived deployments.
Speculative decoding is not enabled: benchmark data shows no net speedup on single-GPU setups, and some draft-model configurations corrupt tool-call JSON.
tmux attach -t llmserver # Ctrl+B then D to detach
Loading takes ~30 seconds. Ready when the log prints:
main: model loaded
main: server is listening on http://0.0.0.0:8080
srv update_slots: all slots are idle
Verify the server is healthy:
curl http://localhost:8080/health
# {"status":"ok"}
Check VRAM in a second SSH window:
nvidia-smi --query-gpu=memory.used,memory.free,utilization.gpu --format=csv
# 31813 MiB, 14255 MiB, 0 %
The 31.8 GB used / 14 GB free reading matches the upstream estimate above. Stepping to 128K context would roughly double the softmax-KV component (~+1 GB) and remain comfortable. Single processing slot; parallel subagent calls serialize. Test:
curl -s http://localhost:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "unsloth/Qwen3.6-35B-A3B",
"messages": [{"role": "user", "content": "Say hello in one sentence."}],
"max_tokens": 4096
}'
The timings block from the response shows 305 tok/s prefill and 133 tok/s decode, 5.5× the 24 tok/s of the previous post’s Qwen3.5-27B on the A10G. Two effects compound: the L40S has 1.4× the A10G’s memory bandwidth (864 vs 600 GB/s), and the 3B-active MoE only moves ~2.5 GB per forward pass against ~13 GB for the 27B-Q4 dense model, a 5.2× reduction in bytes-per-token. Pure bandwidth math gives a 1.4 × 5.2 ≈ 7.3× theoretical ceiling; the measured 5.5× is below that because tokenizer, sampler, JSON serialization, and per-step CUDA-launch overhead add fixed cost per token that doesn’t shrink with the model. The “Say hello” prompt produced 1175 tokens before settling on a one-line answer, so set max_tokens generously; agents truncated mid-thinking produce garbled output.
10. [REMOTE] Validate with ToolCall-15
ToolCall-15 is a BenchLocal benchmark for LLM tool-calling quality: 15 tests across 5 categories. We run version 1.0.1. Since the previous post, it has been refactored from a Vite dashboard into a CLI, so it runs entirely on the remote instance against localhost:8080.
1. In a new tmux window, install Node.js 20 and clone the benchmark:
tmux new-window -t llmserver
curl -fsSL https://deb.nodesource.com/setup_20.x | bash -
apt-get install -y nodejs
cd ~
git clone https://github.com/stevibe/ToolCall-15
cd ToolCall-15
npm install
2. Run the benchmark with the same sampling parameters as llama-server. The model alias must match the --alias from section 9:
npm run cli -- \
--models llamacpp:unsloth/Qwen3.6-35B-A3B \
--temperature 0.6 \
--top-p 0.95 \
--top-k 20 \
--min-p 0
The cli script builds first (~10 seconds) then runs the 15 scenarios sequentially. With thinking on, the full run takes about 8 minutes.
Results
Final scores
- llamacpp:unsloth/Qwen3.6-35B-A3B: 93/100 (28/30) ★★★★★ Excellent
Per-test breakdown:
| # | Test | Status |
|---|---|---|
| TC-01 | Direct Specialist Match | pass |
| TC-02 | Distractor Resistance | pass |
| TC-03 | Implicit Tool Need | pass |
| TC-04 | Unit Handling | pass |
| TC-05 | Date and Time Parsing | pass |
| TC-06 | Multi-Value Extraction | pass |
| TC-07 | Search → Read → Act | pass |
| TC-08 | Conditional Branching | pass |
| TC-09 | Parallel Independence | pass |
| TC-10 | Trivial Knowledge | pass |
| TC-11 | Simple Math | pass |
| TC-12 | Impossible Request | pass |
| TC-13 | Empty Results | pass |
| TC-14 | Malformed Response | fail |
| TC-15 | Conflicting Information | pass |
TC-14 (Malformed Response) is the single failure: “Did not handle the tool error with enough integrity.” When a tool returns garbage, Qwen3.6-35B-A3B does not always re-issue the call cleanly. The previous post’s Qwen3.5-27B scored 29/30 with its miss on TC-11 (trivial math); the 35B-A3B passes TC-11 but is one notch weaker on error recovery. Net quality is similar.
11. Connect OpenCode to the Remote Server
OpenCode is an open-source terminal coding agent that connects to any OpenAI-compatible endpoint. We run it locally, tunnelled to the remote llama-server.
1. Start an SSH tunnel for port 8080 (run locally, -N suppresses the remote shell):
ssh -L 8080:localhost:8080 scaleway-l40s -N &
A plain ssh -L tunnel dies on any network blip and OpenCode then talks to a closed local port. For multi-hour agent runs, autossh auto-reconnects:
autossh -M 0 -o "ServerAliveInterval=30" -o "ServerAliveCountMax=3" \
-L 8080:localhost:8080 scaleway-l40s -N &
2. Verify the tunnel works:
curl http://localhost:8080/health
# {"status":"ok"}
3. Install OpenCode if needed:
curl -fsSL https://opencode.ai/install | bash
4. Create the configuration file:
mkdir -p ~/.config/opencode
cat > ~/.config/opencode/config.json << 'EOF'
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"local-llama": {
"npm": "@ai-sdk/openai-compatible",
"name": "Local Llama Server",
"options": {
"baseURL": "http://localhost:8080/v1",
"apiKey": "not-needed"
},
"models": {
"qwen3.6-35b-a3b": {
"name": "Qwen3.6-35B-A3B"
}
}
}
},
"model": "local-llama/qwen3.6-35b-a3b"
}
EOF
baseURL points at localhost:8080, forwarded via SSH to the remote llama-server. apiKey is required by the schema but ignored by llama-server. For long agent runs, add "max_tokens": 24000 to the model config to leave headroom for the system prompt.
5. Run OpenCode from any project directory:
cd ~/your-project
opencode
12. Using OpenCode with Qwen3.6-35B-A3B
As a test task we asked OpenCode to implement an optimized Jaro-Winkler similarity in Python, the same task as the previous post, so the two runs are comparable:
Implement an optimized Jaro-Winkler similarity in Python.
Requirements:
- Time complexity better than naive O(n²)
- No external libraries, besides Cython, NumPy, Pandas
- Include unit tests
- Handle edge cases (empty strings, identical strings, unicode)
- Benchmark against a naive version
- Vectorize for batch comparison
- Make it NumPy-friendly
- Avoid Python lists for matches (use arrays / bitsets)
OpenCode session, Jaro-Winkler implementation task
Claude Code review
What the model produced
The session produced an 8-file Python package with a Cython acceleration backend, totalling 1,761 lines of source (excluding the 565 KB of generated _cython_accel.c): __init__.py (115 LOC, public API with Cython→pure-Python fallback), _naive.py (67 LOC, reference O(n·m)), _optimized.py (119 LOC, bit-parallel with Python big ints), _batch_numpy.py (162 LOC, NumPy-output batch), _cython_accel.pyx (573 LOC, C-typed hot path), benchmark.py (208 LOC), setup.py (39 LOC), test_jaro_winkler.py (472 LOC, 65 functions, 77 parametrised cases). pytest reports 77 passed in 0.26s.
Bitmasks use Python arbitrary-precision integers (matched_s1, matched_s2), satisfying the “avoid Python lists” requirement. jaro_winkler_batch returns a NumPy array but loops per-pair in Python: output is NumPy-friendly; computation is not vectorised. Unicode handling includes a BMP/supplementary-plane split.
One real bug
The Cython hot path declares unsigned long long matched_s1 and matched_s2, both 64 bits. For strings longer than 64 characters that differ, the position bitmask silently overflows:
>>> from jaro_winkler import jaro_winkler
>>> from jaro_winkler._naive import jaro_winkler_naive
>>> s1 = "a" * 70 + "bbbbb"
>>> s2 = "a" * 70 + "ccccc"
>>> jaro_winkler(s1, s2)
0.7291851851851852
>>> jaro_winkler_naive(s1, s2)
0.9733333333333334
_optimized.py uses Python int (arbitrary precision) for the same masks and does not have this bug; the Cython rewrite kept the algorithm but dropped the precision. The 77-test suite passes because test_very_long_identical uses jaro_winkler(s, s), which hits the py_s1 == py_s2: return 1.0 fast-path and never touches the bitmask code. The fix is either a length guard dispatching to _optimized.py for max(n, m) > 64, or a multi-word bitmask spanning words.
Overall
The model produced a working Python+Cython package with a thoughtful API split, full doctest examples, and 77 unit tests, and made one architecture-level mistake (the 64-bit overflow) the test suite did not catch. As Wes McKinney said in a recent podcast:
[AI-generated code] has to be really rigorously reviewed by other agents and different agent sessions to have any semblance of confidence that you’re shipping something that isn’t totally slop.
13. Stop, Restart, Snapshot, Teardown
All commands below run on the local machine. Three modes matter: running, stopped (compute paused, volume and IP still billed), snapshot-only (instance deleted, only snapshot billed).
Recovering state in a new shell
PROJECT_ID, INSTANCE_ID, SG_ID, VOLUME_ID, and PUBLIC_IP only live in the shell that created them. If you closed the terminal between sessions, re-derive them from tags and names rather than persisting them to a dotfile:
PROJECT_ID=$(scw account project list -o json \
| jq -r '.[] | select(.name=="llm-exploration") | .id')
INSTANCE_ID=$(scw instance server list project-id=$PROJECT_ID -o json \
| jq -r '.[] | select(.tags[]? == "llm-exploration") | .id')
SG_ID=$(scw instance security-group list project-id=$PROJECT_ID -o json \
| jq -r '.[] | select(.name=="llm-exploration-sg") | .id')
# Verify before proceeding.
echo "PROJECT_ID=$PROJECT_ID INSTANCE_ID=$INSTANCE_ID SG_ID=$SG_ID"
VOLUME_ID=$(scw instance server get $INSTANCE_ID zone=fr-par-2 -o json \
| jq -r '.Volumes[0].id')
PUBLIC_IP=$(scw instance server get $INSTANCE_ID zone=fr-par-2 -o json \
| jq -r '.public_ips[0].address')
This works because every resource was created inside a dedicated project (§1 step 3), with a known name or tag. For longer-lived deployments, Terraform / OpenTofu / Pulumi are the right tools.
Stopping llama-server
Ctrl+C inside the tmux session works, but the cleanest one-shot (run on the remote instance) is:
tmux kill-session -t llmserver
This kills the session and the server process in one step, freeing VRAM. Verify:
ss -tlnp | grep 8080 # should print nothing
nvidia-smi --query-gpu=memory.used --format=csv # should drop near 0
Useful if you want to relaunch llama-server with different flags (e.g. a larger --ctx-size) without rebooting the instance.
Stopping the instance
Compute billing pauses. Volume and IP continue at ≈ €0.38/day combined. Everything on the volume survives.
scw instance server stop $INSTANCE_ID zone=fr-par-2
scw instance server wait $INSTANCE_ID zone=fr-par-2
Restarting
scw instance server start $INSTANCE_ID zone=fr-par-2
scw instance server wait $INSTANCE_ID zone=fr-par-2
The public IP is unchanged. Verify if in doubt:
PUBLIC_IP=$(scw instance server get $INSTANCE_ID zone=fr-par-2 \
-o json | jq -r '.public_ips[0].address')
echo $PUBLIC_IP
Your own IP may have drifted. If SSH times out after restart, delete and recreate the security group rule (Scaleway has no in-place update):
MY_IP=$(curl -4 -s ifconfig.me)
# find the old SSH rule's ID and delete it
OLD_RULE_ID=$(scw instance security-group list-rules \
$SG_ID -o json \
| jq -r '.rules[] | select(.dest_port_from==22) | .id')
scw instance security-group delete-rule rule-id=$OLD_RULE_ID
# create the new rule with the current IP
scw instance security-group create-rule \
security-group-id=$SG_ID \
protocol=TCP \
direction=inbound \
action=accept \
ip-range=${MY_IP}/32 \
dest-port-from=22
Reconnect and restart llama-server:
ssh scaleway-l40s
# on the remote instance:
tmux new-session -d -s llmserver '
~/llama-server \
--model ~/models/Qwen3.6-35B-A3B-GGUF/Qwen3.6-35B-A3B-UD-Q6_K_XL.gguf \
--alias "unsloth/Qwen3.6-35B-A3B" \
--jinja \
-ngl 99 \
-fa on \
--ctx-size 65536 \
--cache-type-k q8_0 \
--cache-type-v q8_0 \
--temp 0.6 \
--top-p 0.95 \
--top-k 20 \
--min-p 0.0 \
--presence-penalty 0.0 \
--chat-template-kwargs "{\"enable_thinking\":true,\"preserve_thinking\":true}" \
--host 0.0.0.0 \
--port 8080 2>&1 | tee ~/llmserver.log
'
Re-establish the tunnel locally:
ssh -L 8080:localhost:8080 scaleway-l40s -N &
opencode
Snapshot-only: minimum idle cost
Snapshot storage (€0.000044/GB/hour) is roughly a third of the idle-volume rate (€0.000118/GB/hour) on a per-GB basis. The total monthly bill drops further because a snapshot stores only the used bytes (~51 GB here, vs the full 100 GB volume) and because deleting the instance also releases the routed IP (€2.92/month). Net effect: ~€1.64/month snapshot-only vs ~€11.53/month stopped, about 1/7 the idle cost. Worth it for multi-day pauses.
1. Find the volume ID and snapshot it:
VOLUME_ID=$(scw instance server get $INSTANCE_ID zone=fr-par-2 \
-o json | jq -r '.Volumes[0].id')
echo $VOLUME_ID
SNAPSHOT_ID=$(scw block snapshot create \
volume-id=$VOLUME_ID \
name=llm-exploration-snap-$(date +%Y%m%d) \
zone=fr-par-2 \
project-id=$PROJECT_ID \
-o json | jq -r .id)
echo $SNAPSHOT_ID
scw block snapshot wait $SNAPSHOT_ID zone=fr-par-2
A snapshot bills only on used bytes (~51 GB here).
2. Delete the instance and its volume:
scw instance server delete $INSTANCE_ID \
zone=fr-par-2 \
with-volumes=all \
with-ip=true
with-volumes=all removes the block volume; with-ip=true releases the IP. The snapshot survives.
3. Restore from the snapshot:
NEW_VOLUME_ID=$(scw block volume create \
from-snapshot-id=$SNAPSHOT_ID \
name=llm-exploration-restored \
iops=5000 \
zone=fr-par-2 \
project-id=$PROJECT_ID \
-o json | jq -r .id)
INSTANCE_ID=$(scw instance server create \
type=L40S-1-48G \
zone=fr-par-2 \
root-volume=block:$NEW_VOLUME_ID \
ip=new \
security-group-id=$SG_ID \
project-id=$PROJECT_ID \
tags.0=llm-exploration \
-o json | jq -r .id)
Full teardown
# stop and delete the instance with its volume and IP
scw instance server delete $INSTANCE_ID \
zone=fr-par-2 \
with-volumes=all \
with-ip=true
# delete the security group (must wait for the instance to be gone)
scw instance security-group delete $SG_ID zone=fr-par-2
# if you took a snapshot in the previous subsection, delete it too
[ -n "$SNAPSHOT_ID" ] && scw block snapshot delete $SNAPSHOT_ID zone=fr-par-2
# delete the IAM SSH key (organization-wide, optional)
SSH_KEY_ID=$(scw iam ssh-key list -o json \
| jq -r '.[] | select(.name=="scaleway-l40s") | .id')
scw iam ssh-key delete $SSH_KEY_ID
# kill any local SSH tunnels
pkill -f "ssh.*scaleway-l40s"
# delete the project itself; this fails if any resource is left in it,
# which makes it a good final check
scw account project delete project-id=$PROJECT_ID
If project delete succeeds, every billable resource is gone.
14. Cost
All prices below are in EUR before tax, collected 2026-04-27 from scaleway.com/en/pricing/gpu/ and scaleway.com/en/pricing/storage/, for the fr-par-2 zone.
Before launching, set a budget alert at the Scaleway Console. We configured a €100 budget with a notification trigger at 90%. A forgotten running L40S burns through that in roughly three days, so the alert reaches the inbox while there’s still time to react.
Hourly running cost
| Component | Price | Hourly |
|---|---|---|
| L40S-1-48G compute | €1.40/hour | €1.4000 |
| 100 GB Block Storage 5K IOPS | €0.000118/GB/hour | €0.0118 |
| Zonal Flexible IPv4 (routed) | €0.004/hour | €0.0040 |
| Total running | €1.4158/hour |
Compute dominates. Every Scaleway Instance IPv4 is billable. The session produced lines totalling €3.11: €3.04 compute, €0.05 volume, €0.02 IP. Two notes on the math: (a) per the Scaleway docs, GPU Instances are billed per minute of uptime (including startup and standby), so €3.04 implies ~130 minutes at €0.023332/min (b) Volume and IP might start billing at provisioning, before compute comes up. The Console screenshot below was taken the next morning and shows €3.60: the extra ~€0.49 is overnight idle on the stopped instance, since block volume + Zonal Flexible IP keep ticking at €0.0158/hour while compute is paused.
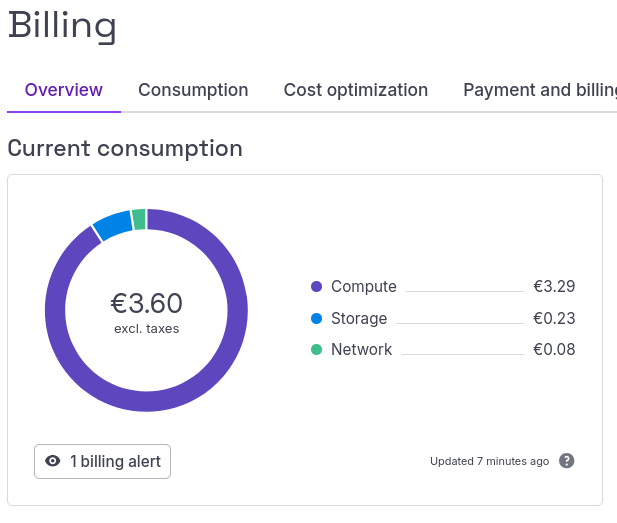
Scaleway Console billing page the morning after the run: €3.60 total (€3.11 active session + overnight idle)
The following idle costs is theoretical, from what we read.
Idle cost: instance stopped
100 GB × €0.000118/GB/hour + €0.004/hour = €0.0158/hour ≈ €11.53/month (≈ €0.38/day).
Idle cost: snapshot only
51 GB × €0.000044/GB/hour = €0.00224/hour ≈ €1.64/month. Restore time is ~5 minutes.
15. Reflections
Compared to the previous post’s A10G, the L40S adds 24 GB of VRAM, Flash Attention hardware, and the MoE architecture; together they yield 5.5× the decode speed at the 35B-A3B scale. The trade-off is €1.41/hour with no spot market; snapshot-only idle should be at ~€1.64/month.
Scaleway was a pleasant surprise: solid CLI, clean web console, two-minute ID verification, transparent billing.
What self-hosting buys over an API remains the same: privacy (code never leaves the instance), cost ceiling (no per-token spikes on long agent runs), and freedom to swap models at the speed of hf download. With Qwen3.6 just landed and the next open-weight model already in training, that last point is the underrated one.